





这是 Cgroup 系列的第四篇,往期回顾:
通过
上篇文章的学习,我们学会了如何查看当前 cgroup 的信息,如何通过操作 /sys/fs/cgroup 目录来动态设置 cgroup,也学会了如何设置 CPU shares 和 CPU quota 来控制 slice 内部以及不同 slice 之间的 CPU 使用时间。本文将继续探讨对 CPU 使用时间的限制。
对于某些 CPU 密集型的程序来说,不仅需要获取更多的 CPU 使用时间,还要减少工作负载在节流时引起的上下文切换。现在的多核系统中每个核心都有自己的缓存,如果频繁的调度进程在不同的核心上执行势必会带来缓存失效等开销。那么有没有方法针对 CPU 核心进行隔离呢?准确地说是把运行的进程绑定到指定的核心上运行。虽然对于操作系统来说,所有程序生而平等,但有些程序比其他程序更平等。
对于那些更平等的程序来说,我们需要为它分配更多的 CPU 资源,毕竟人都是很偏心的。废话少说,我们来看看如何使用 cgroup 限制进程使用指定的 CPU 核心。
1. 查看 CPU 配置#
CPU 核心的编号一般是从 0 开始的,4 个核心的编号范围是 0-3。我们可以通过查看 /proc/cpuinfo 的内容来确定 CPU 的某些信息:
$ cat /proc/cpuinfo
...
processor : 3
vendor_id : GenuineIntel
cpu family : 6
model : 26
model name : Intel(R) Xeon(R) CPU X5650 @ 2.67GHz
stepping : 4
microcode : 0x1f
cpu MHz : 2666.761
cache size : 12288 KB
physical id : 6
siblings : 1
core id : 0
cpu cores : 1
apicid : 6
initial apicid : 6
fpu : yes
fpu_exception : yes
cpuid level : 11
wp : yes
flags : fpu vme de pse tsc msr pae mce cx8 apic sep mtrr pge mca cmov pat pse36 clflush mmx fxsr sse sse2 ss syscall nx rdtscp lm constant_tsc arch_perfmon nopl xtopology tsc_reliable nonstop_tsc eagerfpu pni ssse3 cx16 sse4_1 sse4_2 x2apic popcnt tsc_deadline_timer hypervisor lahf_lm ssbd ibrs ibpb stibp tsc_adjust arat spec_ctrl intel_stibp flush_l1d arch_capabilities
bogomips : 5333.52
clflush size : 64
cache_alignment : 64
address sizes : 43 bits physical, 48 bits virtual
processor: 表示核心的编号,但这不是物理 CPU 的核心,更确切地可以称之为**逻辑核编号。physical id: 表示当前逻辑核所在的物理 CPU 的核心,也是从 0 开始编号,这里表示这个逻辑核在第 7 个 物理 CPU 上。core id: 如果这个值大于 0,你就要注意了,你的服务器可能开启了超线程。如果启用了超线程,每个物理 CPU 核心会模拟出 2 个线程,也叫逻辑核(和上面的逻辑核是两回事,只是名字相同而已)。如果你想确认服务器有没有开启超线程,可以通过下面的命令查看:
$ cat /proc/cpuinfo | grep -e "core id" -e "physical id"
physical id : 0
core id : 0
physical id : 2
core id : 0
physical id : 4
core id : 0
physical id : 6
core id : 0
如果 physical id 和 core id 皆相同的 processor 出现了两次,就可以断定开启了超线程。显然我的服务器没有开启。
2. NUMA 架构#
这里需要涉及到一个概念叫
NUMA(Non-uniform memory access),即非统一内存访问架构。如果主机板上插有多块 CPU,那么就是 NUMA 架构。每块 CPU 独占一块面积,一般都有独立风扇。
一个 NUMA 节点包含了直连在该区域的 CPU、内存等硬件设备,通信总线一般是 PCI-E。由此也引入了 CPU 亲和性的概念,即 CPU 访问同一个 NUMA 节点上的内存的速度大于访问另一个节点的。
可以通过下面的命令查看本机的 NUMA 架构:
$ numactl --hardware
available: 1 nodes (0)
node 0 cpus: 0 1 2 3
node 0 size: 2047 MB
node 0 free: 1335 MB
node distances:
node 0
0: 10
可以看出该服务器并没有使用 NUMA 架构,总共只有一个 NUMA 节点,即只有一块 CPU,4 个逻辑核心均在此 CPU 上。
3. isolcpus#
Linux 最重要的职责之一就是调度进程,而进程只是程序运行过程的一种抽象,它会执行一系列指令,计算机会按照这些指令来完成实际工作。从硬件的角度来看,真正执行这些指令的是中央处理单元,即 CPU。默认情况下,进程调度器可能会将进程调度到任何一个 CPU 核心上,因为它要根据负载来均衡计算资源的分配。
为了增加实验的明显效果,可以隔离某些逻辑核心,让系统默认情况下永远不会使用这些核心,除非我指定某些进程使用这些核心。要想做到这一点,就要使用到内核参数 isolcpus 了,例如:如果想让系统默认情况下不使用逻辑核心 2,3 和 4,可以将以下内容添加到内核参数列表中:
isolcpus=1,2,3
# 或者
isolcpus=1-3
对于 CnetOS 7 来说,可以直接修改 /etc/default/grub:
$ cat /etc/default/grub
GRUB_TIMEOUT=5
GRUB_DISTRIBUTOR="$(sed 's, release .*$,,g' /etc/system-release)"
GRUB_DEFAULT=saved
GRUB_DISABLE_SUBMENU=true
GRUB_TERMINAL_OUTPUT="console"
GRUB_CMDLINE_LINUX="crashkernel=auto rd.lvm.lv=rhel/root rd.lvm.lv=rhel/swap rhgb quiet isolcpus=1,2,3"
GRUB_DISABLE_RECOVERY="true"
然后重新构建 grub.conf:
$ grub2-mkconfig -o /boot/grub2/grub.cfg
重启系统之后,系统将不再使用逻辑核心 2,3 和 4,只会使用核心 1。找个程序把 CPU 跑满( 上篇文章用的程序),使用命令 top 查看 CPU 的使用状况:
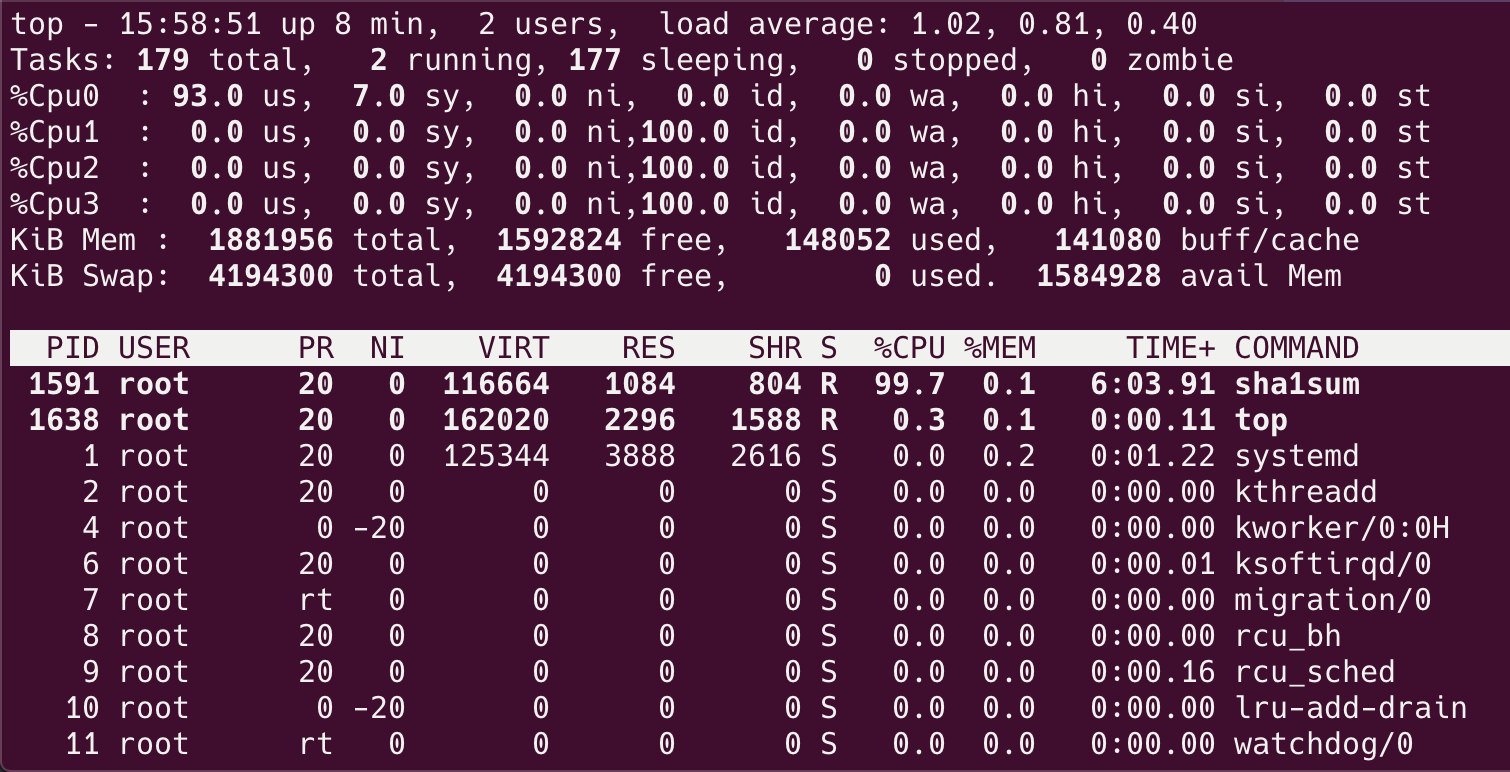
top 命令后,在列表页按数字 1 键,就可以看到所有 CPU 了。可以看到系统只使用了核心 1,下面我们来看看如何将程序绑到特定的 CPU 核心上。
4. 创建 cgroup#
将程序绑到指定的核心其实很简单,只需设置好 cpuset 控制器就行了。 systemctl 可以管理受其控制资源的 cgroup 控制器,但只能管理有限的控制器(CPU、内存和 BlockIO),不能管理 cpuset 控制器。虽然 systemd 不支持 cpuset,但是相信以后会支持的,另外,现在有一个略显笨拙,但是可以实现同样的目标的方法,后面会介绍。
cgroup 相关的所有操作都是基于内核中的 cgroup virtual filesystem,使用 cgroup 很简单,挂载这个文件系统就可以了。文件系统默认情况下都是挂载到 /sys/fs/cgroup 目录下,查看一下这个目录:
$ ll /sys/fs/cgroup
总用量 0
drwxr-xr-x 2 root root 0 3月 28 2020 blkio
lrwxrwxrwx 1 root root 11 3月 28 2020 cpu -> cpu,cpuacct
lrwxrwxrwx 1 root root 11 3月 28 2020 cpuacct -> cpu,cpuacct
drwxr-xr-x 2 root root 0 3月 28 2020 cpu,cpuacct
drwxr-xr-x 2 root root 0 3月 28 2020 cpuset
drwxr-xr-x 4 root root 0 3月 28 2020 devices
drwxr-xr-x 2 root root 0 3月 28 2020 freezer
drwxr-xr-x 2 root root 0 3月 28 2020 hugetlb
drwxr-xr-x 2 root root 0 3月 28 2020 memory
lrwxrwxrwx 1 root root 16 3月 28 2020 net_cls -> net_cls,net_prio
drwxr-xr-x 2 root root 0 3月 28 2020 net_cls,net_prio
lrwxrwxrwx 1 root root 16 3月 28 2020 net_prio -> net_cls,net_prio
drwxr-xr-x 2 root root 0 3月 28 2020 perf_event
drwxr-xr-x 2 root root 0 3月 28 2020 pids
drwxr-xr-x 4 root root 0 3月 28 2020 systemd
可以看到 cpuset 控制器已经默认被创建并挂载好了。看一下 cpuset 目录下有什么:
$ ll /sys/fs/cgroup/cpuset
总用量 0
-rw-r--r-- 1 root root 0 3月 28 2020 cgroup.clone_children
--w--w--w- 1 root root 0 3月 28 2020 cgroup.event_control
-rw-r--r-- 1 root root 0 3月 28 2020 cgroup.procs
-r--r--r-- 1 root root 0 3月 28 2020 cgroup.sane_behavior
-rw-r--r-- 1 root root 0 3月 28 2020 cpuset.cpu_exclusive
-rw-r--r-- 1 root root 0 3月 28 2020 cpuset.cpus
-r--r--r-- 1 root root 0 3月 28 2020 cpuset.effective_cpus
-r--r--r-- 1 root root 0 3月 28 2020 cpuset.effective_mems
-rw-r--r-- 1 root root 0 3月 28 2020 cpuset.mem_exclusive
-rw-r--r-- 1 root root 0 3月 28 2020 cpuset.mem_hardwall
-rw-r--r-- 1 root root 0 3月 28 2020 cpuset.memory_migrate
-r--r--r-- 1 root root 0 3月 28 2020 cpuset.memory_pressure
-rw-r--r-- 1 root root 0 3月 28 2020 cpuset.memory_pressure_enabled
-rw-r--r-- 1 root root 0 3月 28 2020 cpuset.memory_spread_page
-rw-r--r-- 1 root root 0 3月 28 2020 cpuset.memory_spread_slab
-rw-r--r-- 1 root root 0 3月 28 2020 cpuset.mems
-rw-r--r-- 1 root root 0 3月 28 2020 cpuset.sched_load_balance
-rw-r--r-- 1 root root 0 3月 28 2020 cpuset.sched_relax_domain_level
-rw-r--r-- 1 root root 0 3月 28 2020 notify_on_release
-rw-r--r-- 1 root root 0 3月 28 2020 release_agent
-rw-r--r-- 1 root root 0 3月 28 2020 tasks
该目录下只有默认的配置,没有任何 cgroup 子系统。接下来我们来创建 cpuset 子系统并设置相应的绑核参数:
$ mkdir -p /sys/fs/cgroup/cpuset/test
$ echo "3" > /sys/fs/cgroup/cpuset/test/cpuset.cpus
$ echo "0" > /sys/fs/cgroup/cpuset/test/cpuset.mems
首先创建了一个 cpuset 子系统叫 test,然后将核心 4 绑到该子系统,即 cpu3。对于 cpuset.mems 参数而言,每个内存节点和 NUMA 节点一一对应。如果进程的内存需求量较大,可以把所有的 NUMA 节点都配置进去。这里就用到了 NUMA 的概念。出于性能的考虑,配置的逻辑核和内存节点一般属于同一个 NUMA 节点,可用 numactl --hardware 命令获知它们的映射关系。很显然,我的主机没有采用 NUMA 架构,只需将其设为节点 0 就好了。
查看 test 目录:
$ cd /sys/fs/cgroup/cpuset/test
$ ll
总用量 0
-rw-rw-r-- 1 root root 0 3月 28 17:07 cgroup.clone_children
--w--w---- 1 root root 0 3月 28 17:07 cgroup.event_control
-rw-rw-r-- 1 root root 0 3月 28 17:07 cgroup.procs
-rw-rw-r-- 1 root root 0 3月 28 17:07 cpuset.cpu_exclusive
-rw-rw-r-- 1 root root 0 3月 28 17:07 cpuset.cpus
-r--r--r-- 1 root root 0 3月 28 17:07 cpuset.effective_cpus
-r--r--r-- 1 root root 0 3月 28 17:07 cpuset.effective_mems
-rw-rw-r-- 1 root root 0 3月 28 17:07 cpuset.mem_exclusive
-rw-rw-r-- 1 root root 0 3月 28 17:07 cpuset.mem_hardwall
-rw-rw-r-- 1 root root 0 3月 28 17:07 cpuset.memory_migrate
-r--r--r-- 1 root root 0 3月 28 17:07 cpuset.memory_pressure
-rw-rw-r-- 1 root root 0 3月 28 17:07 cpuset.memory_spread_page
-rw-rw-r-- 1 root root 0 3月 28 17:07 cpuset.memory_spread_slab
-rw-rw-r-- 1 root root 0 3月 28 17:07 cpuset.mems
-rw-rw-r-- 1 root root 0 3月 28 17:07 cpuset.sched_load_balance
-rw-rw-r-- 1 root root 0 3月 28 17:07 cpuset.sched_relax_domain_level
-rw-rw-r-- 1 root root 0 3月 28 17:07 notify_on_release
-rw-rw-r-- 1 root root 0 3月 28 17:07 tasks
$ cat cpuset.cpus
3
$ cat cpuset.mems
0
目前 tasks 文件是空的,也就是说,还没有进程运行在该 cpuset 子系统上。需要想办法让指定的进程运行在该子系统上,有两种方法:
- 将已经运行的进程的
PID写入tasks文件中; - 使用
systemd创建一个守护进程,将 cgroup 的设置写入service文件中(本质上和方法 1 是一样的)。
先来看看方法 1,首先运行一个程序:
$ nohup sha1sum /dev/zero &
[1] 3767
然后将 PID 写入 test 目录的 tasks 中:
$ echo "3767" > /sys/fs/cgroup/cpuset/test/tasks
查看 CPU 使用情况:
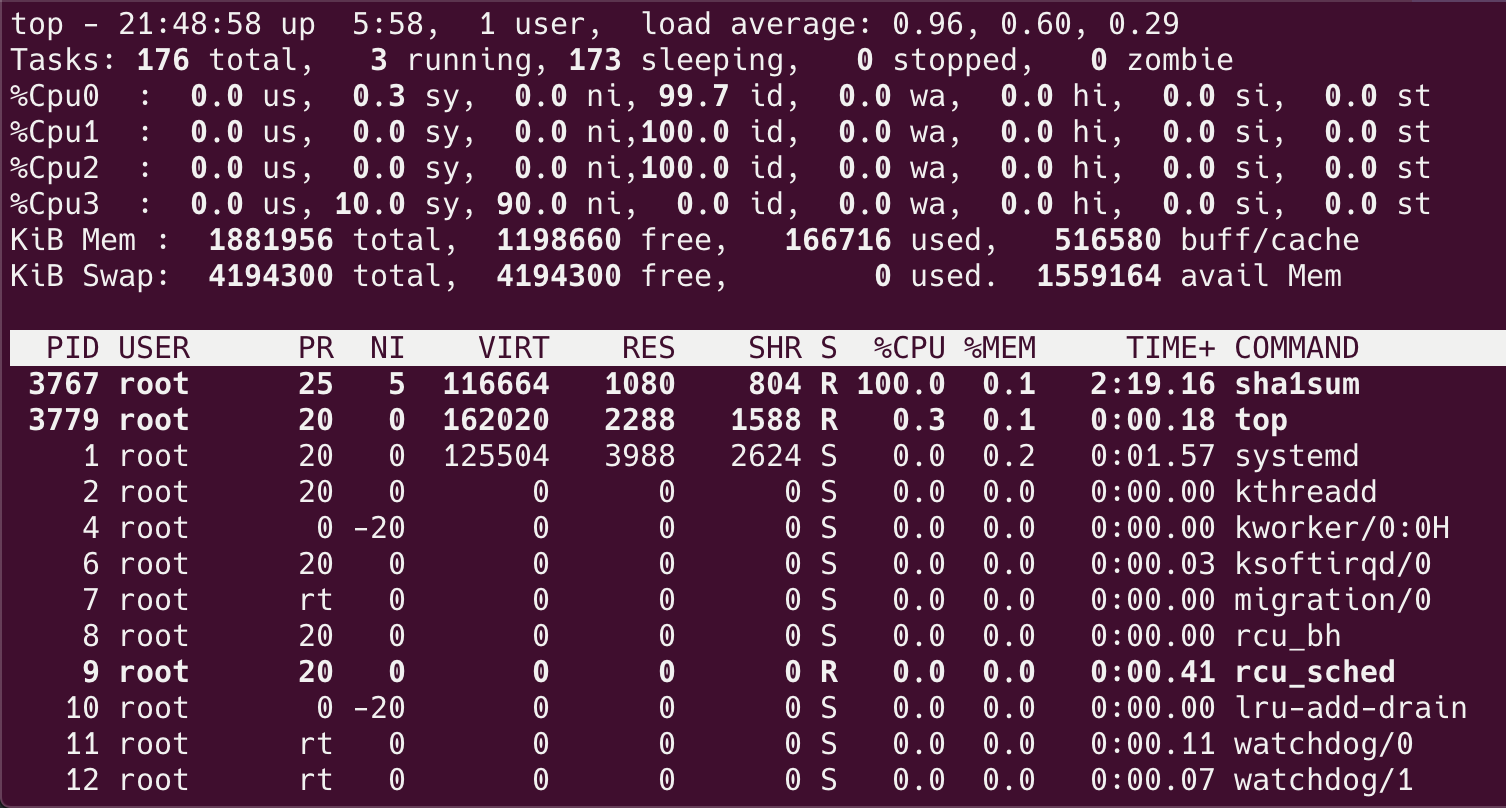
可以看到绑核生效了,PID 为 3767 的进程被调度到了 cpu3 上。
下面再来看看方法 2,虽然目前 systemd 不支持使用 cpuset 去指定一个 Service 的 CPU,但我们还是有一个变相的方法,Service 文件内容如下:
$ cat /etc/systemd/system/foo.service
[Unit]
Description=foo
After=syslog.target network.target auditd.service
[Service]
ExecStartPre=/usr/bin/mkdir -p /sys/fs/cgroup/cpuset/testset
ExecStartPre=/bin/bash -c '/usr/bin/echo "2" > /sys/fs/cgroup/cpuset/testset/cpuset.cpus'
ExecStartPre=/bin/bash -c '/usr/bin/echo "0" > /sys/fs/cgroup/cpuset/testset/cpuset.mems'
ExecStart=/bin/bash -c "/usr/bin/sha1sum /dev/zero"
ExecStartPost=/bin/bash -c '/usr/bin/echo $MAINPID > /sys/fs/cgroup/cpuset/testset/tasks'
ExecStopPost=/usr/bin/rmdir /sys/fs/cgroup/cpuset/testset
Restart=on-failure
[Install]
WantedBy=multi-user.target
启动该服务,然后查看 CPU 使用情况:
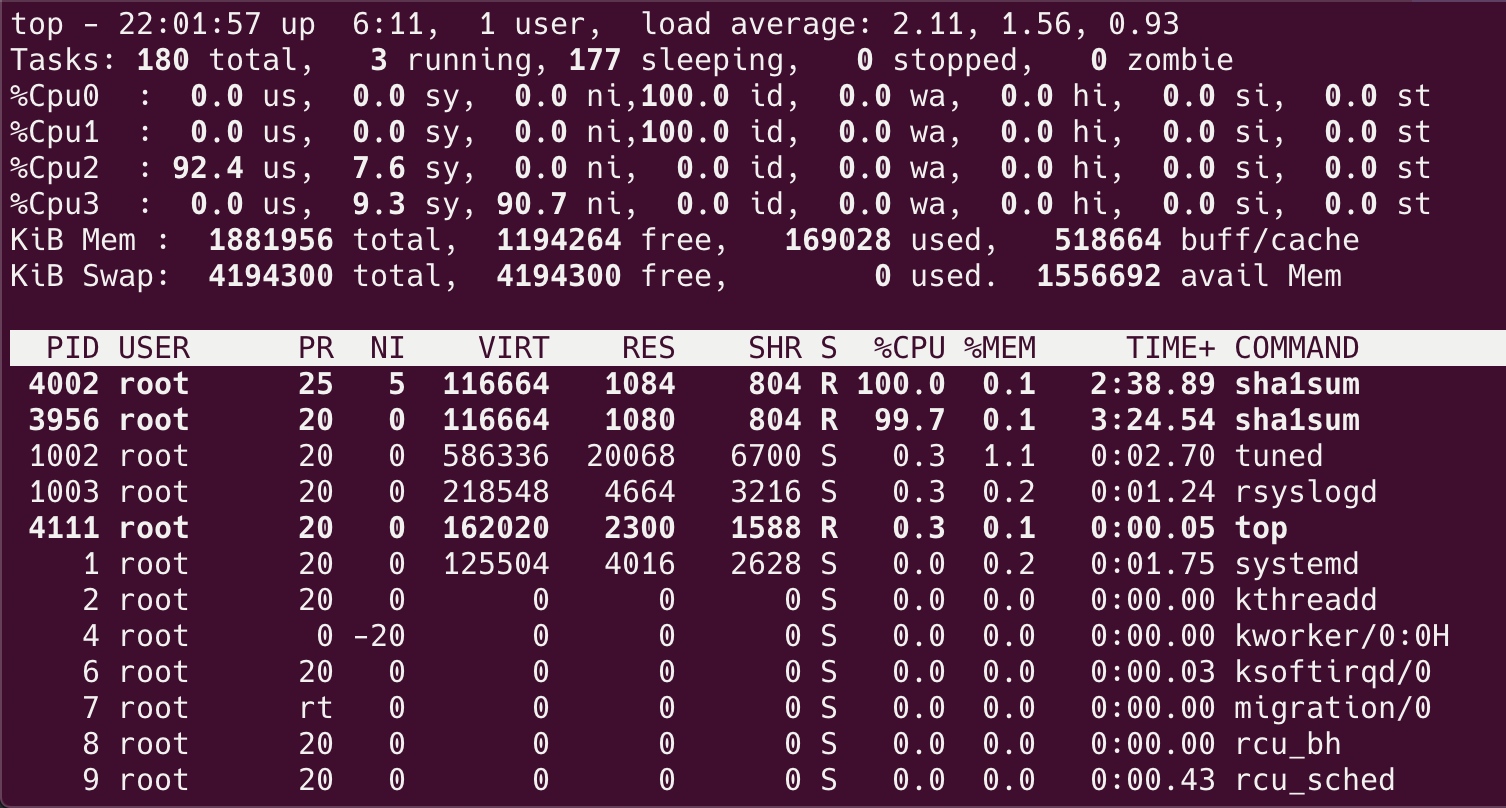
该服务中的进程确实被调度到了 cpu2 上。
5. 回到 Docker#
最后我们回到 Docker,Docker 实际上就是将系统底层实现的 cgroup 、 namespace 等技术集成在一个使用镜像方式发布的工具中,于是形成了 Docker,这个想必大家都知道了,我就不展开了。对于 Docker 来说,有没有办法让容器始终在一个或某几个 CPU 上运行呢?其实还是很简单的,只需要利用 --cpuset-cpus 参数就可以做到!
下面就来演示一下,指定运行容器的 CPU 核心编号为 1:
🐳 → docker run -d --name stress --cpuset-cpus="1" progrium/stress -c 4
查看主机 CPU 的负载:
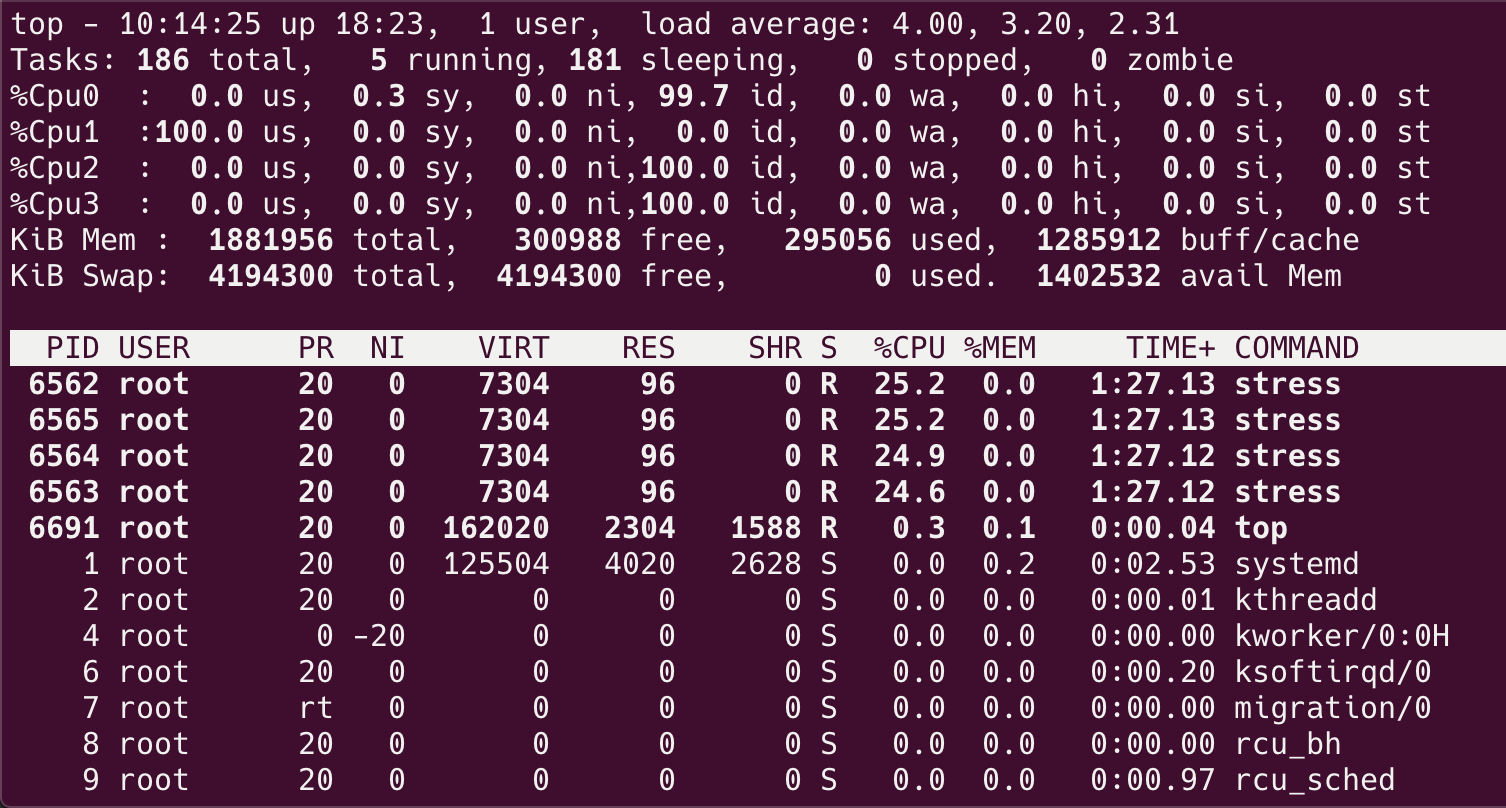
只有 Cpu1 达到了 100%,其它的 CPU 并未被容器使用。
如果你看过该系列的
第一篇文章,应该知道,在新的使用 systemd 实现 init 的系统中(比如 ConetOS 7),系统默认创建了 3 个顶级 slice:System, User 和 Machine,其中 machine.slice 是所有虚拟机和 Linux 容器的默认位置,而 Docker 其实是 machine.slice 的一个变种,你可以把它当成 machine.slice 。
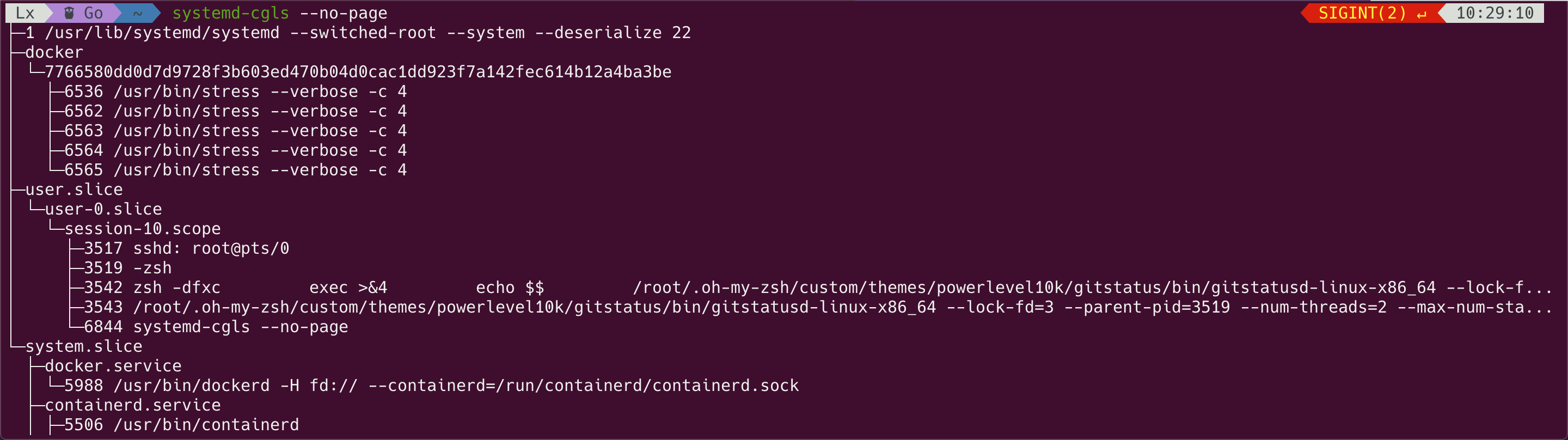
如果系统中运行的是 Kubernetes,machine.slice 就变成了 kubepods:
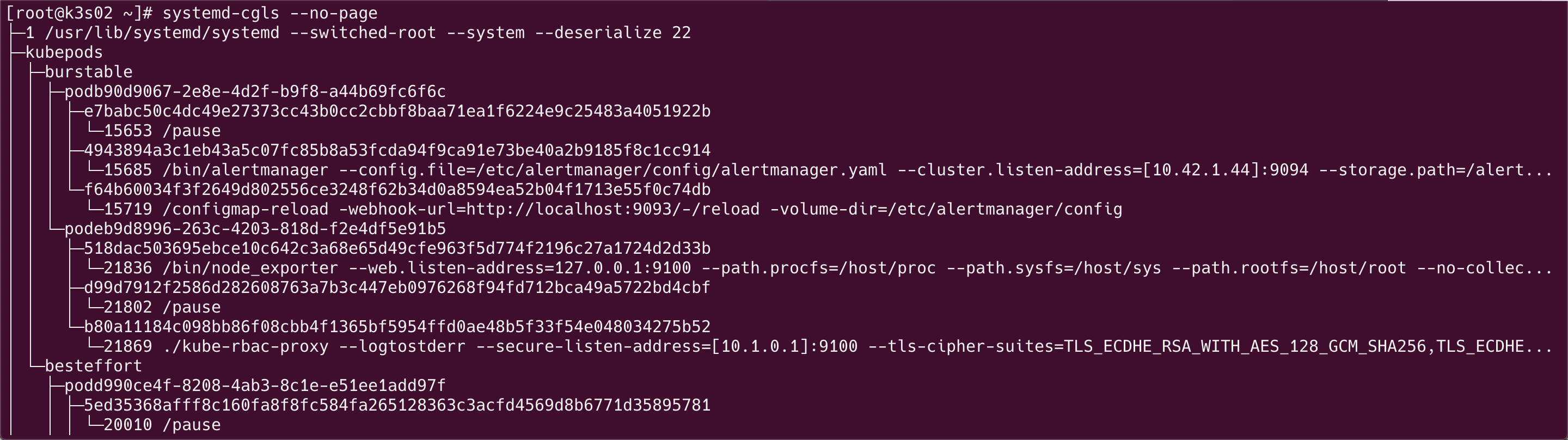
为了便于管理 cgroup,systemd 会为每一个 slice 创建一个子系统,比如 docker 子系统:
然后再根据容器的设置,将其放入相应的控制器下面,这里我们关心的是 cpuset 控制器,看看它的目录下有啥:
查看 docker 目录:
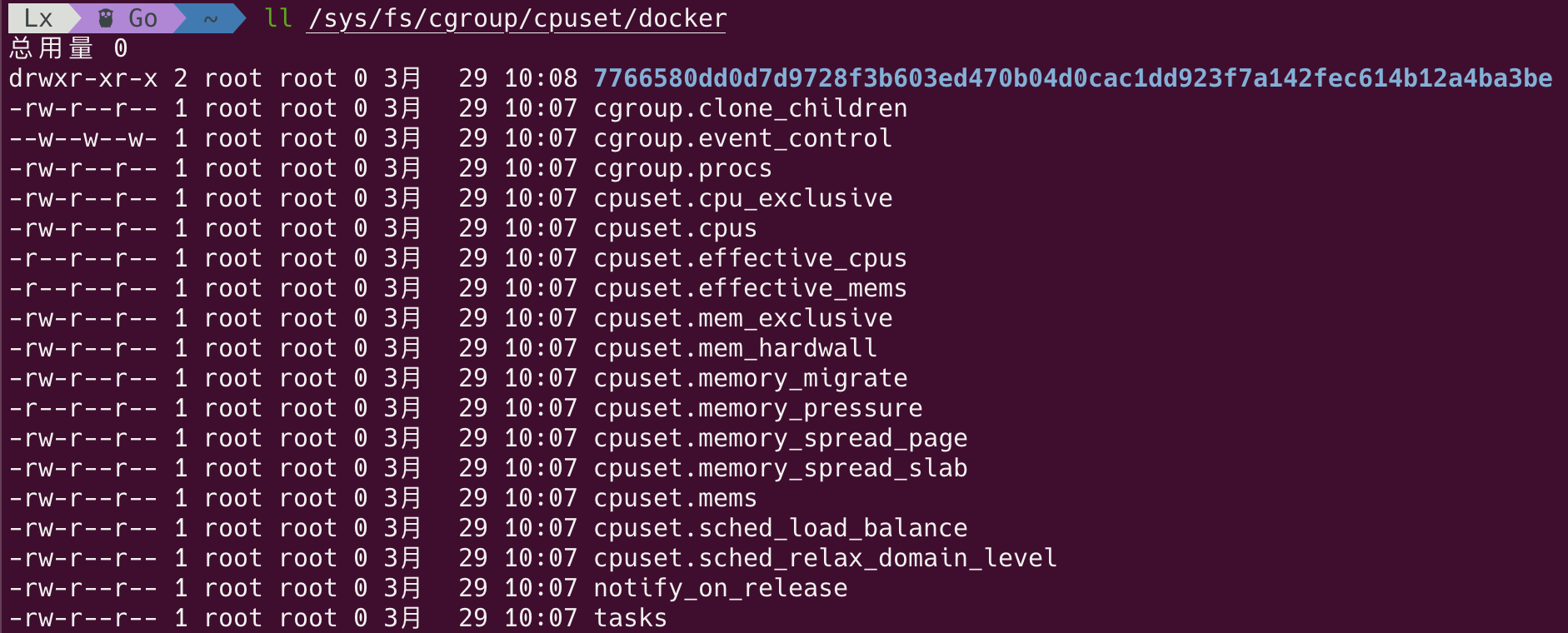
可以看到 Docker 为每个容器创建了一个子目录,7766.. 对应的就是之前我们创建的容器:
🐳 → docker ps|grep stress
7766580dd0d7 progrium/stress "/usr/bin/stress --v…" 36 minutes ago Up 36 minutes stress
我们来检验一下该目录下的配置:
$ cd /sys/fs/cgroup/cpuset/docker/7766580dd0d7d9728f3b603ed470b04d0cac1dd923f7a142fec614b12a4ba3be
$ cat cpuset.cpus
1
$ cat cpuset.mems
0
$ cat tasks
6536
6562
6563
6564
6565
$ ps -ef|grep stress
root 6536 6520 0 10:08 ? 00:00:00 /usr/bin/stress --verbose -c 4
root 6562 6536 24 10:08 ? 00:09:50 /usr/bin/stress --verbose -c 4
root 6563 6536 24 10:08 ? 00:09:50 /usr/bin/stress --verbose -c 4
root 6564 6536 24 10:08 ? 00:09:50 /usr/bin/stress --verbose -c 4
root 6565 6536 24 10:08 ? 00:09:50 /usr/bin/stress --verbose -c 4
当然,你也可以将容器绑到多个 CPU 核心上运行,这里我就不赘述了。下篇文章将会介绍如何通过 cgroup 来限制 BlockIO。