





本文我们将从实践者的角度仔细研究整个pod生命周期,包括如何影响启动和关闭行为,并通过实践来理解对应用程序健康状况的检查。
Pod 的生命周期#
Pod phase#
Pod 的 status 在信息保存在 PodStatus 中定义,其中有一个 phase 字段。
Pod 的相位(phase)是 Pod 在其生命周期中的简单宏观概述。该阶段并不是对容器或 Pod 的综合汇总,也不是为了做为综合状态机。
Pod 相位的数量和含义是严格指定的。除了本文档中列举的状态外,不应该再假定 Pod 有其他的 phase 值。
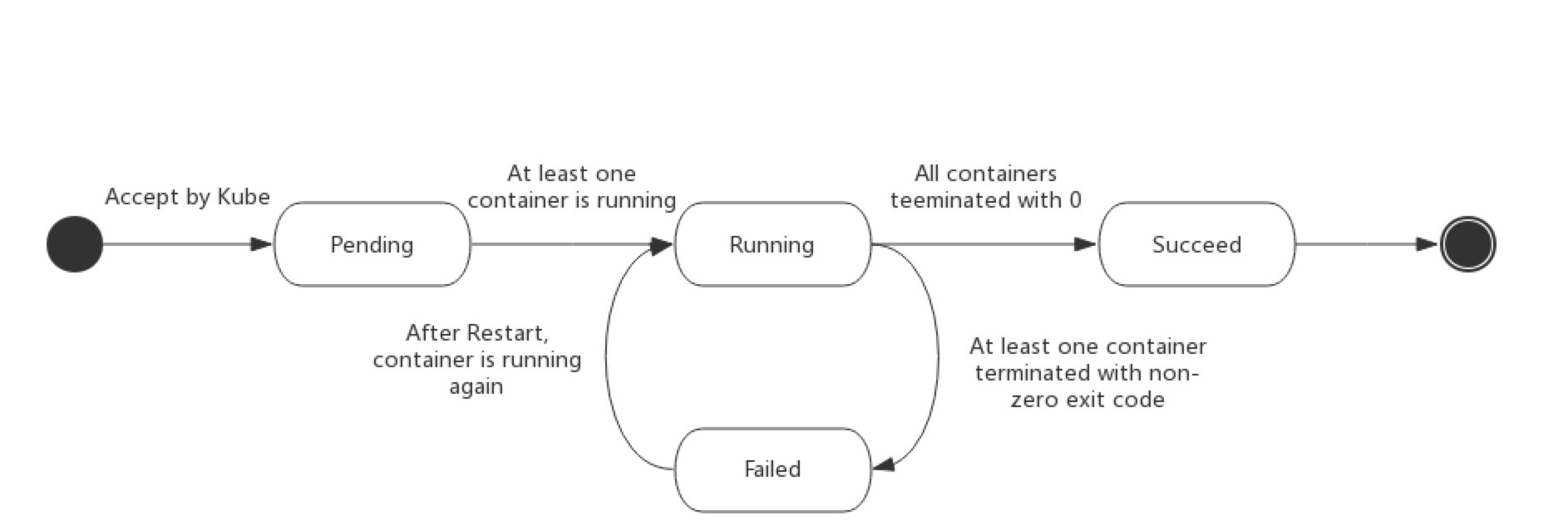
无论你是手动创建 Pod,还是通过 deployment、daemonset 或 statefulset来创建,Pod 的 phase 都有以下几个可能的值:
- 挂起(Pending):Pod 已被 Kubernetes 系统接受,但有一个或者多个容器镜像尚未创建。等待时间包括调度 Pod 的时间和通过网络下载镜像的时间,这可能需要花点时间。
- 运行中(Running):该 Pod 已经绑定到了一个节点上,Pod 中所有的容器都已被创建。至少有一个容器正在运行,或者正处于启动或重启状态。
- 成功(Successed):Pod 中的所有容器都被成功终止,并且不会再重启。
- 失败(Failed):Pod 中的所有容器都已终止了,并且至少有一个容器是因为失败终止。也就是说,容器以非0状态退出或者被系统终止。
- 未知(Unkonwn):因为某些原因无法取得 Pod 的状态,通常是因为与 Pod 所在主机通信失败。
下图是 Pod 的生命周期示意图,从图中可以看到 Pod 状态的变化。
Pod 状态#
Pod 有一个 PodStatus 对象,其中包含一个
PodCondition 数组。 PodCondition 数组的每个元素都有一个 type 字段和一个 status 字段。type 字段是字符串,可能的值有 PodScheduled、Ready、Initialized 和 Unschedulable。status 字段是一个字符串,可能的值有 True、False 和 Unknown。
当你通过 kubectl get pod 查看 Pod 时,STATUS 这一列可能会显示与上述5个状态不同的值,例如 Init:0/1 和 CrashLoopBackOff。这是因为 Pod 状态的定义除了包含 phase 之外,还有 InitContainerStatuses 和 containerStatuses 等其他字段,具体代码参考
overall status of a pod .
如果想知道究竟发生了什么,可以通过命令 kubectl describe pod/$PODNAME 查看输出信息的 Events 条目。通过 Events 条目可以看到一些具体的信息,比如正在拉取容器镜像,Pod 已经被调度,或者某个 container 处于 unhealthy 状态。
Pod 的启动关闭流程#
下面通过一个具体的示例来探究一下 Pod 的整个生命周期流程。为了确定事情发生的顺序,通过下面的 manifest 来部署一个 deployment。
kind: Deployment
apiVersion: apps/v1beta1
metadata:
name: loap
spec:
replicas: 1
template:
metadata:
labels:
app: loap
spec:
initContainers:
- name: init
image: busybox
command: ['sh', '-c', 'echo $(date +%s): INIT >> /loap/timing']
volumeMounts:
- mountPath: /loap
name: timing
containers:
- name: main
image: busybox
command: ['sh', '-c', 'echo $(date +%s): START >> /loap/timing;
sleep 10; echo $(date +%s): END >> /loap/timing;']
volumeMounts:
- mountPath: /loap
name: timing
livenessProbe:
exec:
command: ['sh', '-c', 'echo $(date +%s): LIVENESS >> /loap/timing']
readinessProbe:
exec:
command: ['sh', '-c', 'echo $(date +%s): READINESS >> /loap/timing']
lifecycle:
postStart:
exec:
command: ['sh', '-c', 'echo $(date +%s): POST-START >> /loap/timing']
preStop:
exec:
command: ['sh', '-c', 'echo $(date +%s): PRE-HOOK >> /loap/timing']
volumes:
- name: timing
hostPath:
path: /tmp/loap
等待 Pod 状态变为 Running 之后,通过以下命令来强制停止 Pod:
$ kubectl scale deployment loap --replicas=0
查看 /tmp/loap/timing 文件的内容:
$ cat /tmp/loap/timing
1525334577: INIT
1525334581: START
1525334581: POST-START
1525334584: READINESS
1525334584: LIVENESS
1525334588: PRE-HOOK
1525334589: END
/tmp/loap/timing 文件的内容很好地体现了 Pod 的启动和关闭流程,具体过程如下:
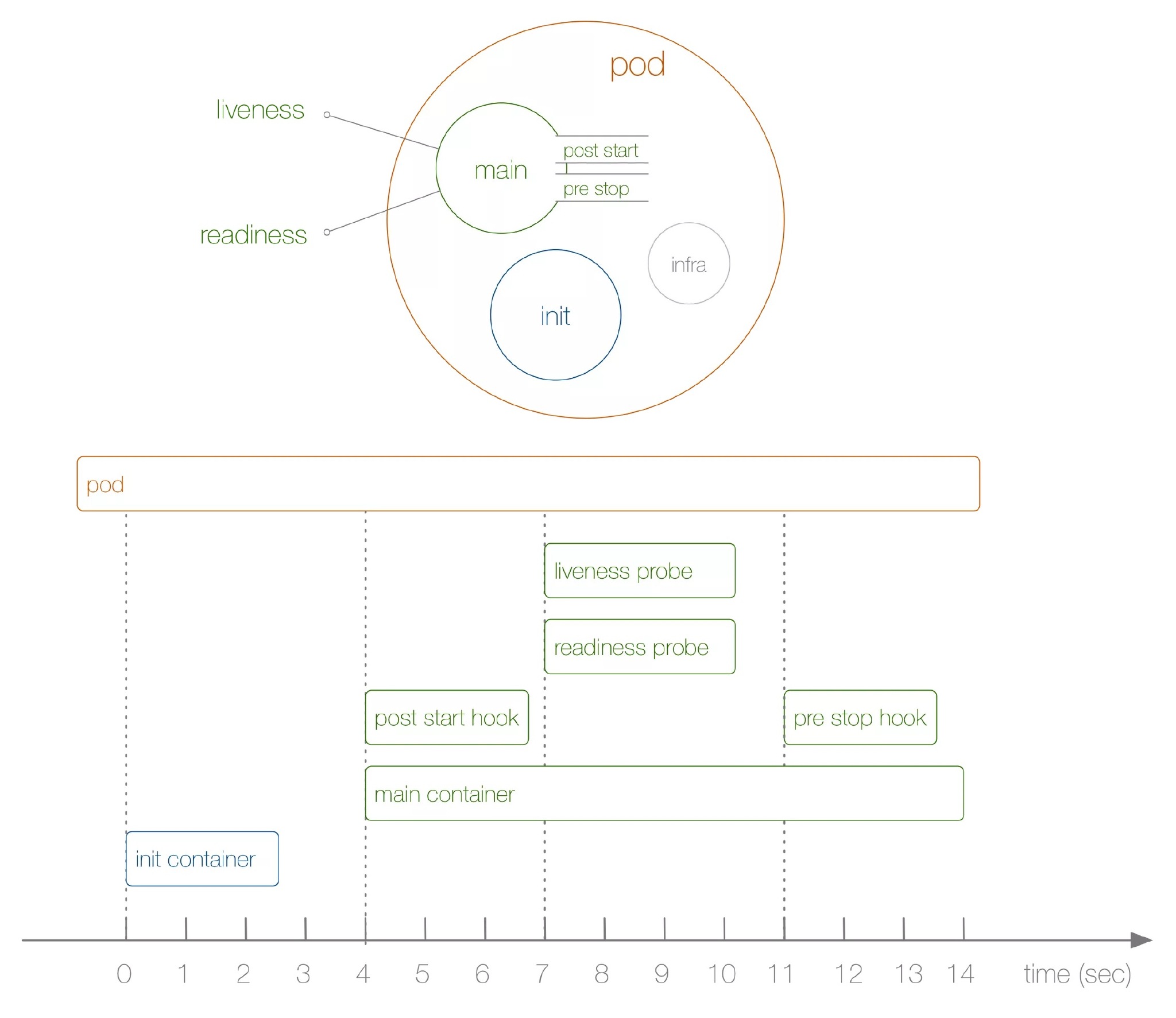
- 首先启动一个 Infra 容器(又叫 Pause 容器),用来和 Pod 中的其他容器共享 linux 命名空间,并开启 init 进程。(上图中忽略了这一步)
- 然后启动 Init 容器,它是一种专用的容器,在应用程序容器启动之前运行,用来对 Pod 进行一些初始化操作,并包括一些应用镜像中不存在的实用工具和安装脚本。
- 4 秒之后,应用程序容器和
post-start hook同时启动。 - 7 秒之后开始启动 liveness 和 readiness 探针。
- 11 秒之后,通过手动杀掉 Pod,
pre-stop hook执行,优雅删除期限过期后(默认是 30 秒),应用程序容器停止。实际的 Pod 终止过程要更复杂,具体参考 Pod 的终止。
pre-stop hook,如果是 Pod 自己 Down 掉,则不会执行 pre-stop hook。如何快速 DEBUG#
当 Pod 出现致命的错误时,如果能够快速 DEBUG,将会帮助我们快速定位问题。为了实现这个目的,可以把把致命事件的信息通过 .spec.terminationMessagePath 配置写入指定位置的文件,就像打印错误、异常和堆栈信息一样。该位置的内容可以很方便的通过 dashboards、监控软件等工具检索和展示,默认路径为 /dev/termination-log。
以下是一个小例子:
# termination-demo.yaml
apiVersion: v1
kind: Pod
metadata:
name: termination-demo
spec:
containers:
- name: termination-demo-container
image: alpine
command: ["/bin/sh"]
args: ["-c", "sleep 10 && echo Sleep expired > /dev/termination-log"]
这些消息的最后部分会使用其他的规定来单独存储:
$ kubectl create -f termination-demo.yaml
$ sleep 20
$ kubectl get pod termination-demo -o go-template='{{range .status.containerStatuses}}{{.lastState.terminated.message}}{{end}}'
Sleep expired
$ kubectl get pod termination-demo -o go-template='{{range .status.containerStatuses}}{{.lastState.terminated.exitCode}}{{end}}'
0