





原文链接:Optimizing Kubernetes resource allocation in production
我和 Kubernetes 的初次接触就涉及到将应用容器化并部署到生产环境集群中,当时我的工作重点是把 buffer 吞吐量最高(低风险)的某个端点从单个应用程序中分离出来,因为这个特殊的端点会给我们带来很大的困扰,偶尔还会影响到其他更高优先级的流量。
在使用 curl 进行一些手动测试之后,我们决定将这个剥离出来的端点部署在 Kubernetes 上。当有 1% 的流量打进来时,服务运行正常,一切看起来都是那么地美好;当流量增加到 10% 时,也没有什么大问题;最后我将流量增加到 50%,麻烦来了,这时候服务突然陷入了 crash 循环状态。当时我的第一反应是将该服务的副本数扩到 20 个,扩完之后有一点成效,但没过多久 Pod 仍然陷入 crash 循环状态。通过 kubectl describe 查看审计日志,我了解到 Kubelet 因为 OOMKilled 杀掉了 Pod,即内存不足。深入挖掘后,我找到了问题根源,当时我从另一个 deployment 文件中复制粘贴 YAML 内容时设置了一些严格的内存限制,从而导致了上述一系列问题。这段经历让我开始思考如何才能有效地设置资源的 requests 和 limits。
请求(requests)和限制(limits)#
Kubernetes 允许在 CPU,内存和本地存储(v1.12 中的 beta 特性)等资源上设置可配置的请求和限制。像 CPU 这样的资源是可压缩的,这意味着对 CPU 资源的限制是通过
CPU 管理策略来控制的。而内存等其他资源都是不可压缩的,它们都由 Kubelet 控制,如果超过限制就会被杀死。使用不同的 requests 和 limits 配置,可以为每个工作负载实现不同的服务质量(QoS)。
Limits#
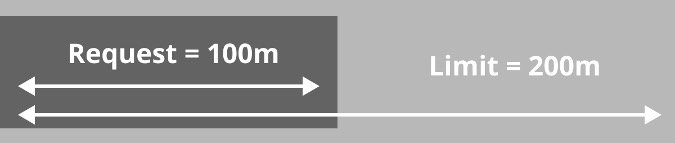
limits 表示允许工作负载消耗资源的上限,如果资源的使用量越过配置的限制阈值将会触发 Kubelet 杀死 Pod。如果没有设置 limits,那么工作负载可以占用给定节点上的所有资源;如果有很多工作负载都没有设置 limits,那么资源将会被尽最大努力分配。
Requests#
调度器使用 requests 来为工作负载分配资源,工作负载可以使用所有 requests 资源,而无需 Kubernetes 的干预。如果没有设置 limits 并且资源的使用量超过了 requests 的阈值,那么该容器的资源使用量很快会被限制到低于 requests 的阈值。如果只设置了 limits,Kubernetes 会自动把对应资源的 requests 设置成和 limits 一样。
QoS(服务质量)#
在 Kubernetes 中通过资源和限制可以实现三种基本的 QoS,QoS 的最佳配置主要还是取决于工作负载的需求。
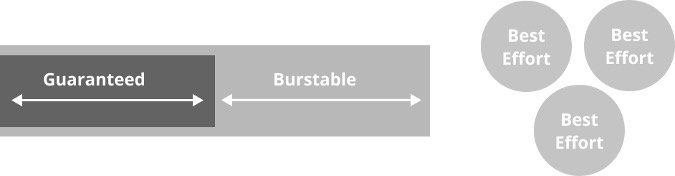
Guaranteed QoS#
通过只设置 limits 而不设置 requests 就可以实现 Guaranteed QoS,这意味着容器可以使用调度器为其分配的所有资源。对于绑定 CPU 和具有相对可预测性的工作负载(例如,用来处理请求的 Web 服务)来说,这是一个很好的 QoS 等级。

Burstable QoS#
通过配置 CPU 或内存的 limits 和 requests,并且 requests < limits,就可以实现 Burstable QoS。这意味着容器的资源使用量可以达到 requests 阈值,同时如果该容器运行的节点上资源充足,那么容器可以继续使用资源,只要不超过 limits 阈值就行。这对短时间内需要消耗大量资源或者初始化过程很密集的工作负载非常有用,例如:用来构建 Docker 容器的 Worker 和运行未优化的 JVM 进程的容器都可以使用该 QoS 等级。
Best effort QoS#
通过既不设置 limits 也不设置 requests,可以实现 Best effort QoS。这意味着容器可以使用宿主机上任何可用的资源。从调度器的角度来看,这是最低优先级的任务,并且会在 Burstable QoS Pod 和 Guaranteed QoS Pod 之前被先杀掉。这对于可中断和低优先级的工作负载非常有用,例如:迭代运行的幂等优化过程。

设置 requests 和 limits#
设置 limits 和 requests 的关键是找到单个 Pod 的断点。通过使用几种不同的负载测试技术,可以在应用程序部署到生产环境之前对应用程序的故障模式有一个全面的了解。当资源使用量达到限制阈值时,几乎每个应用程序都有自己的一组故障模式。
在准备测试之前,请确保将 Pod 的副本数设置为 1,并且将 limits 设置为一组保守的数字,例如:
# limits might look something like
replicas: 1
...
cpu: 100m # ~1/10th of a core
memory: 50Mi # 50 Mebibytes
注意 : 在测试过程中设置 limits 非常重要,它可以让我们看到预期的效果(在内存较高时限制 CPU 并杀死 Pod)。在测试的迭代过程中,最好每次只更改一种资源限制(CPU 或内存),不要同时更改。
负载增加测试#
负载增加测试会随着时间的推移增加负载,直到负载下的服务突然失败或测试完成。
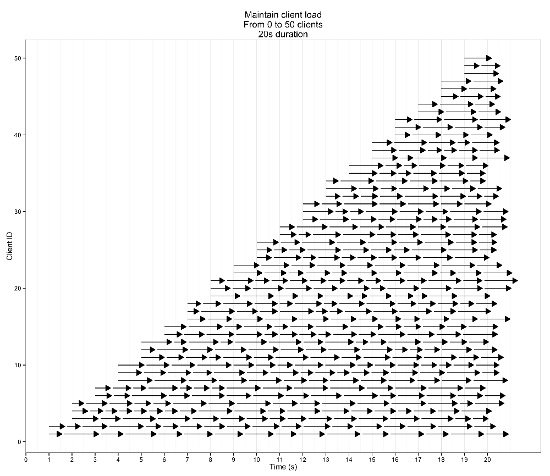
如果负载增加测试突然失败,则表明资源限制过于严格,这是一个很好的迹象。当观察到图像有明显抖动时,将资源限制增加一倍并重复,直到测试成功完成。
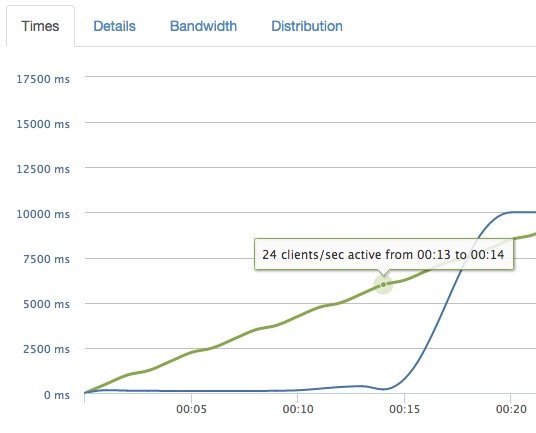
当资源限制接近最优时,性能应该随着时间的推移而可预测地降低(至少对于 Web 服务而言应该是这样)。
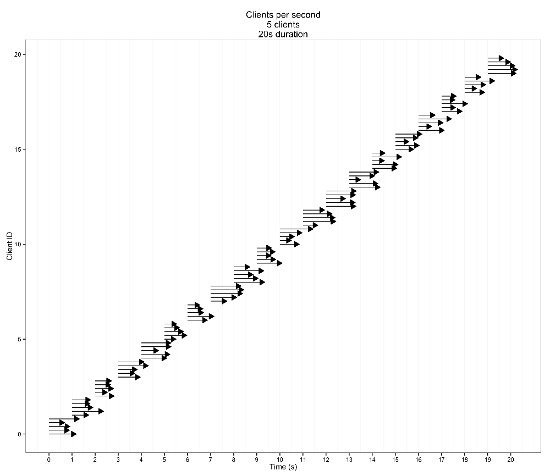
如果在增加负载的过程中性能并没有太大的变化,则说明为工作负载分配了太多的资源。
负载不变测试#
在运行负载增加测试并调整资源限制之后,下一步就开始进行负载不变测试。负载不变测试会在一段很长的时间内(至少 10 分钟,时间再长一点更好)对应用施加相同的负载,至于加多少负载,最好选择在图像出现断点之前的压力值(例如:客户端数量)。
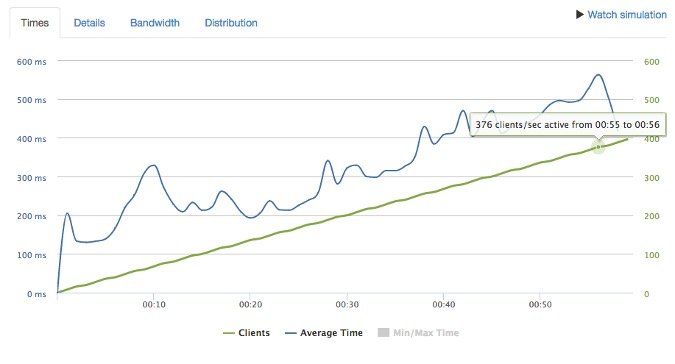
此测试的目的是识别内存泄漏和隐藏的排队机制,因为这些机制在负载增加测试中很难被捕获到。到了这个阶段,即使还要对资源限制进行调整,调整的幅度也应该很小。理想情况下,该阶段测试期间性能应该会保持稳定。
记录失败日志#
在测试过程中,记录服务失败时做了哪些操作是至关重要的。可以将发现的故障模式添加到相关的书籍和文档中,这对分类生产环境中出现的问题很有用。下面是我们在测试过程中发现的一些故障模式:
- 内存缓慢增加
- CPU 使用率达到 100%
- 响应时间太长
- 请求被丢弃
- 不同请求的响应时间差异很大
你最好将这些发现都收集起来,以备不时之需,因为有一天它们可能会为你或团队节省一整天的时间。
一些有用的工具#
虽然你可以使用 Apache Bench 等工具来增加负载,也可以使用 cAdvisor 来可视化资源使用率,但这里我要介绍一些更适合负载测试的工具。
Loader.io#
Loader.io 是一个在线负载测试工具,它允许你配置负载增加测试和负载不变测试,在测试过程中可视化应用程序的性能和负载,并能快速启动和停止测试。它也会保存测试结果的历史记录,因此在资源限制发生变化时很容易对结果进行比较。
Kubescope cli#
Kubescope cli 是一个可以运行在本地或 Kubernetes 中的工具,可直接从 Docker Daemon 中收集容器指标并可视化。和 cAdvisor 等其他集群指标收集服务一样, kubescope cli 收集指标的周期是 1 秒(而不是 10-15 秒)。如果周期是 10-15 秒,你可能会在测试期间错过一些引发性能瓶颈的问题。如果你使用 cAdvisor 进行测试,每次都要使用新的 Pod 作为测试对象,因为 Kubernetes 在超过资源限制时就会将 Pod 杀死,然后重新启动一个全新的 Pod。而 kubescope cli 就没有这方面的忧虑,它直接从 Docker Daemon 中收集容器指标(你可以自定义收集指标的时间间隔),并使用正则表达式来选择和过滤你想要显示的容器。
总结#
我发现在搞清楚服务什么时候会出现故障以及为什么会出现故障之前,不应该将其部署到生产环境中。我希望您能从我的错误中吸取教训,并通过一些技术手段来设置应用的资源 limits 和 requests。这将会为你的系统增加弹性能力和可预测性,使你的客户更满意,并有望帮助你获得更多的睡眠。