





原文链接:Kubernetes zero downtime deployment: when theory meets the database
如果你使用像 Gmail 这样的在线服务或者大型社交媒介和电子商务平台,你可能从来都没有遇到过哪个页面会提示你“请等待我们的应用更新完成”。
事实上,现如今越来越多的服务需要始终保持启用和可访问的状态,主要有以下几个原因:
- 如果你竞争对手的应用可以保持不宕机,那你可能会失去竞争优势;换句话说,如果你的竞争对手没法保持不宕机,而你的应用可以始终保持服务可用,那你就具有竞争优势。
- 在全球范围内,用户体验质量在不断提高,用户希望随着时间的推移能够提高应用的可用性。
- 如果你的应用会直接影响到你的收入,例如,以电子商务应用的形式进行销售。那么你应该能意识到宕机可能导致的业务影响。
虽然意外宕机不能完全避免,但在更新应用时保持零宕机还是有可能的。
先驱:蓝绿部署#
最早用来实现零宕机更新的方法是 蓝绿部署,简而言之,蓝绿部署规定应该有两个完全相似的环境,一个代表绿,一个代表蓝。无论任何时候,都有一个环境运行生产级别的应用,另一个环境运行预生产级别的应用。在集群的流量入口处有一个调度器,用来将请求路由到相应的环境:生产或预生产。当某个应用需要更新时,首先将它部署到预生产环境,进行一系列测试,然后将流量切换到该环境,使之暂时成为新的生产环境,反之亦然。
在使用蓝绿部署的过程中,会遇到下面几个问题:
用来路由请求的调度器必须是零延迟。
一旦完成流量切换,环境就会发生转换,用户的流量就会被路由到新环境。调度器的实现有很多种方式:路由器、软件代理等,可能很难实现零延迟切换。
当切换流量时,如果用户和应用已经发生了交互会怎么样?
现代架构的终极目标是实现应用的弹性伸缩和无状态化。但实际情况下有些应用无法完全实现无状态化:比如购物车的无状态化就很难实现,唯一的办法是在购物车状态发生变化时将其从 A 环境迁移到 B 环境。但环境的迁移不是瞬间完成的,用户可能会发现自己处于中间状态,既不是完全处于 A 环境中,也不是完全处于 B 环境中。
如果应用后端有数据库该如何处理?
和上面讨论的类似,如果有一个 A 环境的数据库和一个 B 环境的数据库,就需要把数据从 A 环境迁移到 B 环境。推荐的做法是在流量切换之前完成数据的迁移,但在生产环境中数据可能会在流量完全切换之前发生变化,因此流量切换完成之后还要再进行一次数据迁移。但数据的迁移也不是瞬间完成的,需要一定的时间,这段时间内用户可能无法使用该服务。
折中的解决方案是将数据库转移到 AB 环境之外的环境,然后将数据共享给 A 和 B 这两个环境。虽然这种架构对隔离性会产生一定的影响,但本文我不会展开详述。
Kubernetes 的滚动更新#
如果你的应用部署在 Kubernetes 中,完全可以通过 Deployment 来实现应用的无缝升级。
Deployment 控制器为 Pod 和 ReplicaSet 提供了声明式更新。关于声明式的详细信息可以参考: Kubernetes 设计与开发原则
你可以在 Deployment 对象中声明期望的状态,Deployment Controller 可以通过不同的策略来不断调整实际状态,直到与期望状态保持一致。你可以选择让 Deployment 创建新的 ReplicaSet 来更新应用,或者删除旧的 Deployment,修改配置后重新创建新的 Deployment。
重点在于“通过不同的控制策略”:这意味着 Deployment 中的 Pod 可以一个一个更新,也可以以两个为一组进行更新,或者先删除所有的 Pod,再创建新的 Pod,你可以有多种选择。具体的配置如下:
apiVersion: apps/v1
kind: Deployment
spec:
replicas: 3
strategy:
rollingUpdate:
maxSurge: 0 # ②
maxUnavailable: 1 # ③
type: RollingUpdate # ①
- ① :
type表示新的 Pod 替换旧的 Pod 的策略,可以是Recreate或者RollingUpdate。如果选择了Recreate,就会在创建出新的 Pod 之前会先杀掉所有已存在的 Pod。这种策略不能实现零宕机升级,所以只能用在开发环境中。如果选择了RollingUpdate,Deployment 就会使用滚动的方式更新 Pod,你可以指定maxUnavailable和maxSurge来控制 rolling update 进程。 - ② :
maxSurge用来指定可以超过期望的 Pod 数量的最大个数。该值可以是一个绝对值(例如 5)或者是期望的 Pod 数量的百分比(例如 10%)。 - ③ :
maxUnavailable用来指定在升级过程中不可用 Pod 的最大数量。该值可以是一个绝对值(例如 5),也可以是期望 Pod 数量的百分比(例如 10%)。
光看理论可能不太好理解,下面我们通过一些示例来理解它的工作原理。
Kubernetes 滚动更新实践#
下文中展示的图表显示了随着时间的推移,不同版本的 Pod 数量的变化:
- 竖轴表示 Pod 的数量
- 蓝色代表 v1 版本的 Pod
- 深蓝色代表 v2 版本的 Pod
- 横轴表示时间
先创建一个新 Pod,再删除一个旧 Pod#
上面的示例 yaml 表示更新过程中最多允许比期望的 Pod 数量多一个 Pod(maxSurge = 1),且最多允许比期望的 Pod 数量少 0 个 Pod(maxUnavailable = 0)。
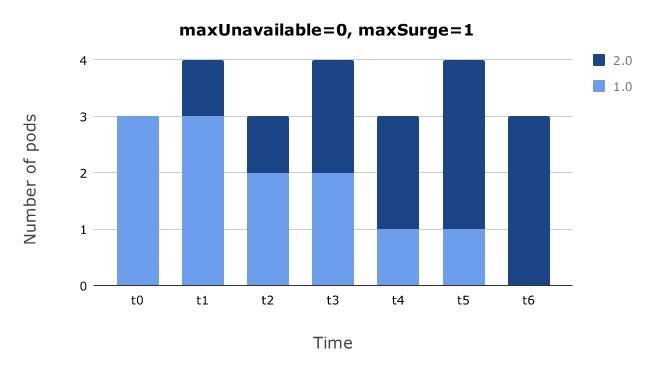
通过该配置,Kubernetes 会创建一个新 Pod,然后再删除一个旧 Pod,不断迭代下去。如果有其他计算节点可以运行新的 Pod,调度系统就会将新 Pod 调度到其他节点,否则就会调度到已有的计算节点,和节点上的其他 Pod 共同竞争计算资源。
先删除一个旧 Pod,再创建一个新 Pod#
如果想在更新过程中最多允许比期望的 Pod 数量多 0 个 Pod,且最多允许比期望的 Pod 数量少 1 个 Pod,可以令 maxSurge = 0,maxUnavailable = 1。
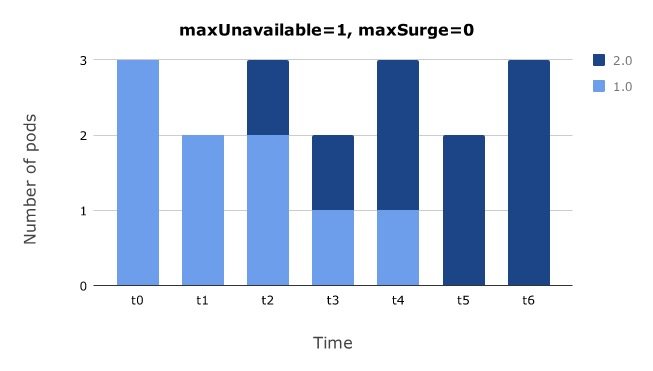
通过该配置,Kubernetes 会删除一个旧 Pod,然后再创建一个新 Pod,不断迭代下去。这种方式的好处是当集群的计算资源不足时,可以保持工作负载的数量不会大于现有的数量。
尽快更新所有 Pod#
如果想在更新过程中最多允许比期望的 Pod 数量多 1 个 Pod,且最多允许比期望的 Pod 数量少 1 个 Pod,可以令 maxSurge = 1,maxUnavailable = 1。
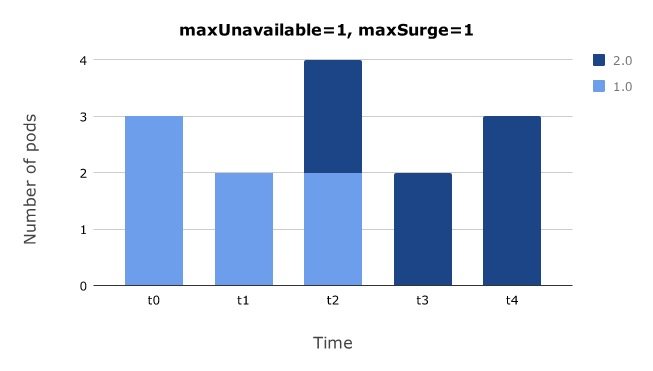
这种配置会尽快更新所有 Pod,大大减少了在应用版本之间切换所需的时间,但包含了前两种方式的所有缺点。
考虑应用启动耗时#
Pod 从启动到能对外提供服务所用的时间是不容忽视的,为了确保容器在部署后确实处在正常运行状态,Kubernetes 提供了两种探针(Probe)来探测容器的状态:
LivenessProbe:探测应用是否处于健康状态,如果不健康则删除并重新创建容器。ReadinessProbe:探测应用是否启动完成并且处于正常服务状态,如果不正常则不会接收来自 Kubernetes Service 的流量。
默认情况下,这两种探针的成功返回值都是 Success,这就有可能会出现问题,因为 Pod 启动成功后,服务不一定会立即可用,这时如果 Service 将流量转发到该 Pod,不会有正确的响应。
为了解决这个问题,应用需要提供给 Kubernetes 查询并能返回应用状态的端点。例如,假如我们在应用中添加了一个 /ready 端点,如果能处理请求就返回 200 状态码,否则就返回 500 状态码。
通过下面的 yaml 可以将 /ready 端点与 Kubernetes 的就绪探针结合使用:
spec:
containers:
- name: foo-app
image: zerodowntime:1.0
readinessProbe:
httpGet:
path: /ready
port: 8080
initialDelaySeconds: 10 ①
periodSeconds: 2 ②
- ① : 第一次就绪检查前需要等待的时间。
- ② : 两次就绪检查间隔的时间。
通过上述配置,只有当 Pod 中的应用能够处理流量时,Service 才会将流量转发到该 Pod。
现在我们已经知道了如何正确处理像 “Hello World” 这种类型的应用,但 Kubernetes 的滚动更新会遇到与蓝绿部署相同的问题:数据库的数据结构变更需要向前向后兼容。
滚动更新与数据结构的兼容性#
上文提到过,数据库结构的更改必须向后兼容。下面用一个简单的示例来说明这个问题。
假设数据库的数据结构如下:

使用这种数据结构,PERSON 和 ADDRESS 之间的界限比较模糊,为了划清界限,可以将数据结构改成如下的形式:
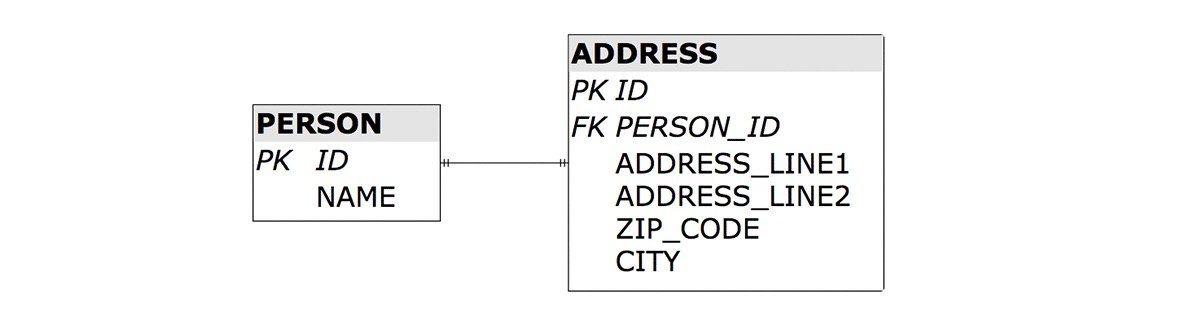
假设原来数据结构界限比较模糊的应用已经在生产环境中开始使用,现在我们的目标是在零宕机的情况下将数据结构更换成上图的最终架构。
为了实现这个目标,我们可以设计一个同时可以处理新数据结构和旧数据结构的新版本应用,这样就可以直接通过滚动更新 Deployment 来更新数据结构。这个方案看起来比较合理,但还有一个问题:Deployment 不能回滚,因为旧版本的应用程序无法处理新的数据结构。因此,我们必须保证应用既能向后兼容,又能向前兼容。看来我们又回到了原点,因为数据结构不可能保证既能向前又能向后兼容。
最好的办法是将数据结构的更新拆分成一系列小的数据结构更新。此外,应用需要以增量的方式进行更新,以便新版本的应用能够处理当前和以后的数据结构更新。具体的数据迁移步骤如下:
1. 将需要更新的应用打上标签 2.1。更新过程中需要在数据库中创建一个 ADDRESS 表,PERSON 表中的每一个变化,都复制一份到 ADDRESS 表中:
对 PERSON 表的操作 | 复制到 ADDRESS 表 |
|---|---|
INSERT | 将相同的数据 INSERT 到 ADDRESS 表中 |
UPDATE | 首先检查 ADDRESS 表中是否有该记录,如果没有该记录,就先创建一个新的记录,然后再更新和 PERSON 中相同的记录;如果有该记录,就直接更新。 |
DELETE | 首先检查 ADDRESS 表中是否有该记录,如果有该记录,就将其删除。 |
这种做法肯定是向前兼容的,因为 1.0 版本的应用直接忽略了 ADDRESS 表。
数据复制大致有两种方法:可以通过数据库来触发数据复制,也可以通过应用程序来触发。即使要通过数据库来触发,也要由应用来创建相应的触发器。
2. 继续滚动更新,标签改为 2.2。和上面相反,ADDRESS 表中的每一个变化,都复制一份到 PERSON 表中。这是因为上面一步的更新过程中,旧版本的应用可能还没来得及更新数据库就被杀死了,这一步可以确保数据完全同步。考虑到兼容性,2.1 版本的应用会继续使用 PERSON 表。
3. 继续滚动更新,标签改为 2.3。更新过程中需要从 PERSON 表中删除多余的字段,最终变成上文所述的最终数据结构。从这一步回滚到上一步也是向前兼容的,因为 2.2 版本的应用的所有数据都来自 ADDRESS 表,2.3 版本只是删除了 PERSON 表中的某些字段,所以 2.2 版本的应用完全可以处理 2.3 版本应用的数据结构。
总结#
尽管滚动更新背后的原理非常简单,但很少有人能在生产环境中利用好它,因为大多数情况下我们都忘记了 deployment 回滚的兼容性。即使你解决了本文提出的问题,也会有新的问题涌现,这就是实现零宕机架构的成本,无法避免。
关于零宕机的理论部分就讲到这里,想必大家都已经理解了,如果你想通过实际的项目来实践,可以参考下一篇文章: 在 Kubernetes 中实现零宕机部署 Spring Boot 应用。