





Kubernetes 中的 Service 就是一组同 label 类型 Pod 的服务抽象,为服务提供了负载均衡和反向代理能力,在集群中表示一个微服务的概念。kube-proxy 组件则是 Service 的具体实现,了解了 kube-proxy 的工作原理,才能洞悉服务之间的通信流程,再遇到网络不通时也不会一脸懵逼。
kube-proxy 有三种模式:userspace、iptables 和 IPVS,其中 userspace 模式不太常用。iptables 模式最主要的问题是在服务多的时候产生太多的 iptables 规则,非增量式更新会引入一定的时延,大规模情况下有明显的性能问题。为解决 iptables 模式的性能问题,v1.11 新增了 IPVS 模式(v1.8 开始支持测试版,并在 v1.11 GA),采用增量式更新,并可以保证 service 更新期间连接保持不断开。
目前网络上关于 kube-proxy 工作原理的文档几乎都是以 iptables 模式为例,很少提及 IPVS,本文就来破例解读 kube-proxy IPVS 模式的工作原理。为了理解地更加彻底,本文不会使用 Docker 和 Kubernetes,而是使用更加底层的工具来演示。
我们都知道,Kubernetes 会为每个 Pod 创建一个单独的网络命名空间 (Network Namespace) ,本文将会通过手动创建网络命名空间并启动 HTTP 服务来模拟 Kubernetes 中的 Pod。
本文的目标是通过模拟以下的 Service 来探究 kube-proxy 的 IPVS 和 ipset 的工作原理:
apiVersion: v1
kind: Service
metadata:
name: app-service
spec:
clusterIP: 10.100.100.100
selector:
component: app
ports:
- protocol: TCP
port: 8080
targetPort: 8080
跟着我的步骤,最后你就可以通过命令 curl 10.100.100.100:8080 来访问某个网络命名空间的 HTTP 服务。为了更好地理解本文的内容,推荐提前阅读以下的文章:
- How do Kubernetes and Docker create IP Addresses?!
- iptables: How Docker Publishes Ports
- iptables: How Kubernetes Services Direct Traffic to Pods
注意:本文所有步骤皆是在 Ubuntu 20.04 中测试的,其他 Linux 发行版请自行测试。
准备实验环境#
首先需要开启 Linux 的路由转发功能:
$ sysctl --write net.ipv4.ip_forward=1
接下来的命令主要做了这么几件事:
- 创建一个虚拟网桥
bridge_home - 创建两个网络命名空间
netns_dustin和netns_leah - 为每个网络命名空间配置 DNS
- 创建两个 veth pair 并连接到
bridge_home - 给
netns_dustin网络命名空间中的 veth 设备分配一个 IP 地址为10.0.0.11 - 给
netns_leah网络命名空间中的 veth 设备分配一个 IP 地址为10.0.021 - 为每个网络命名空间设定默认路由
- 添加 iptables 规则,允许流量进出
bridge_home接口 - 添加 iptables 规则,针对
10.0.0.0/24网段进行流量伪装
$ ip link add dev bridge_home type bridge
$ ip address add 10.0.0.1/24 dev bridge_home
$ ip netns add netns_dustin
$ mkdir -p /etc/netns/netns_dustin
echo "nameserver 114.114.114.114" | tee -a /etc/netns/netns_dustin/resolv.conf
$ ip netns exec netns_dustin ip link set dev lo up
$ ip link add dev veth_dustin type veth peer name veth_ns_dustin
$ ip link set dev veth_dustin master bridge_home
$ ip link set dev veth_dustin up
$ ip link set dev veth_ns_dustin netns netns_dustin
$ ip netns exec netns_dustin ip link set dev veth_ns_dustin up
$ ip netns exec netns_dustin ip address add 10.0.0.11/24 dev veth_ns_dustin
$ ip netns add netns_leah
$ mkdir -p /etc/netns/netns_leah
echo "nameserver 114.114.114.114" | tee -a /etc/netns/netns_leah/resolv.conf
$ ip netns exec netns_leah ip link set dev lo up
$ ip link add dev veth_leah type veth peer name veth_ns_leah
$ ip link set dev veth_leah master bridge_home
$ ip link set dev veth_leah up
$ ip link set dev veth_ns_leah netns netns_leah
$ ip netns exec netns_leah ip link set dev veth_ns_leah up
$ ip netns exec netns_leah ip address add 10.0.0.21/24 dev veth_ns_leah
$ ip link set bridge_home up
$ ip netns exec netns_dustin ip route add default via 10.0.0.1
$ ip netns exec netns_leah ip route add default via 10.0.0.1
$ iptables --table filter --append FORWARD --in-interface bridge_home --jump ACCEPT
$ iptables --table filter --append FORWARD --out-interface bridge_home --jump ACCEPT
$ iptables --table nat --append POSTROUTING --source 10.0.0.0/24 --jump MASQUERADE
在网络命名空间 netns_dustin 中启动 HTTP 服务:
$ ip netns exec netns_dustin python3 -m http.server 8080
打开另一个终端窗口,在网络命名空间 netns_leah 中启动 HTTP 服务:
$ ip netns exec netns_leah python3 -m http.server 8080
测试各个网络命名空间之间是否能正常通信:
$ curl 10.0.0.11:8080
$ curl 10.0.0.21:8080
$ ip netns exec netns_dustin curl 10.0.0.21:8080
$ ip netns exec netns_leah curl 10.0.0.11:8080
整个实验环境的网络拓扑结构如图:

安装必要工具#
为了便于调试 IPVS 和 ipset,需要安装两个 CLI 工具:
$ apt install ipset ipvsadm --yes
本文使用的 ipset 和 ipvsadm 版本分别为
7.5-1~exp1和1:1.31-1。
通过 IPVS 来模拟 Service#
下面我们使用 IPVS 创建一个虚拟服务 (Virtual Service) 来模拟 Kubernetes 中的 Service :
$ ipvsadm \
--add-service \
--tcp-service 10.100.100.100:8080 \
--scheduler rr
- 这里使用参数
--tcp-service来指定 TCP 协议,因为我们需要模拟的 Service 就是 TCP 协议。 - IPVS 相比 iptables 的优势之一就是可以轻松选择调度算法,这里选择使用轮询调度算法。
目前 kube-proxy 只允许为所有 Service 指定同一个调度算法,未来将会支持为每一个 Service 选择不同的调度算法,详情可参考文章 IPVS-Based In-Cluster Load Balancing Deep Dive。
创建了虚拟服务之后,还得给它指定一个后端的 Real Server,也就是后端的真实服务,即网络命名空间 netns_dustin 中的 HTTP 服务:
$ ipvsadm \
--add-server \
--tcp-service 10.100.100.100:8080 \
--real-server 10.0.0.11:8080 \
--masquerading
该命令会将访问 10.100.100.100:8080 的 TCP 请求转发到 10.0.0.11:8080。这里的 --masquerading 参数和 iptables 中的 MASQUERADE 类似,如果不指定,IPVS 就会尝试使用路由表来转发流量,这样肯定是无法正常工作的。
译者注:由于 IPVS 未实现
POST_ROUTINGHook 点,所以它需要 iptables 配合完成 IP 伪装等功能。
测试是否正常工作:
$ curl 10.100.100.100:8080
实验成功,请求被成功转发到了后端的 HTTP 服务!
在网络命名空间中访问虚拟服务#
上面只是在 Host 的网络命名空间中进行测试,现在我们进入网络命名空间 netns_leah 中进行测试:
$ ip netns exec netns_leah curl 10.100.100.100:8080
哦豁,访问失败!
要想顺利通过测试,只需将 10.100.100.100 这个 IP 分配给一个虚拟网络接口。至于为什么要这么做,目前我还不清楚,我猜测可能是因为网桥 bridge_home 不会调用 IPVS,而将虚拟服务的 IP 地址分配给一个网络接口则可以绕过这个问题。
译者注#
Netfilter 是一个基于用户自定义的 Hook 实现多种网络操作的 Linux 内核框架。Netfilter 支持多种网络操作,比如包过滤、网络地址转换、端口转换等,以此实现包转发或禁止包转发至敏感网络。
针对 Linux 内核 2.6 及以上版本,Netfilter 框架实现了 5 个拦截和处理数据的系统调用接口,它允许内核模块注册内核网络协议栈的回调功能,这些功能调用的具体规则通常由 Netfilter 插件定义,常用的插件包括 iptables、IPVS 等,不同插件实现的 Hook 点(拦截点)可能不同。另外,不同插件注册进内核时需要设置不同的优先级,例如默认配置下,当某个 Hook 点同时存在 iptables 和 IPVS 规则时,iptables 会被优先处理。
Netfilter 提供了 5 个 Hook 点,系统内核协议栈在处理数据包时,每到达一个 Hook 点,都会调用内核模块中定义的处理函数。调用哪个处理函数取决于数据包的转发方向,进站流量和出站流量触发的 Hook 点是不一样的。
内核协议栈中预定义的回调函数有如下五个:
- NF_IP_PRE_ROUTING: 接收的数据包进入协议栈后立即触发此回调函数,该动作发生在对数据包进行路由判断(将包发往哪里)之前。
- NF_IP_LOCAL_IN: 接收的数据包经过路由判断后,如果目标地址在本机上,则将触发此回调函数。
- NF_IP_FORWARD: 接收的数据包经过路由判断后,如果目标地址在其他机器上,则将触发此回调函数。
- NF_IP_LOCAL_OUT: 本机产生的准备发送的数据包,在进入协议栈后立即触发此回调函数。
- NF_IP_POST_ROUTING: 本机产生的准备发送的数据包或者经由本机转发的数据包,在经过路由判断之后,将触发此回调函数。
iptables 实现了所有的 Hook 点,而 IPVS 只实现了 LOCAL_IN、LOCAL_OUT、FORWARD 这三个 Hook 点。既然没有实现 PRE_ROUTING,就不会在进入 LOCAL_IN 之前进行地址转换,那么数据包经过路由判断后,会进入 LOCAL_IN Hook 点,IPVS 回调函数如果发现目标 IP 地址不属于该节点,就会将数据包丢弃。
如果将目标 IP 分配给了虚拟网络接口,内核在处理数据包时,会发现该目标 IP 地址属于该节点,于是可以继续处理数据包。
dummy 接口#
当然,我们不需要将 IP 地址分配给任何已经被使用的网络接口,我们的目标是模拟 Kubernetes 的行为。Kubernetes 在这里创建了一个 dummy 接口,它和 loopback 接口类似,但是你可以创建任意多的 dummy 接口。它提供路由数据包的功能,但实际上又不进行转发。dummy 接口主要有两个用途:
- 用于主机内的程序通信
- 由于 dummy 接口总是 up(除非显式将管理状态设置为 down),在拥有多个物理接口的网络上,可以将 service 地址设置为 loopback 接口或 dummy 接口的地址,这样 service 地址不会因为物理接口的状态而受影响。
看来 dummy 接口完美符合实验需求,那就创建一个 dummy 接口吧:
$ ip link add dev dustin-ipvs0 type dummy
将虚拟 IP 分配给 dummy 接口 dustin-ipvs0 :
$ ip addr add 10.100.100.100/32 dev dustin-ipvs0
到了这一步,仍然访问不了 HTTP 服务,还需要另外一个黑科技:bridge-nf-call-iptables。在解释 bridge-nf-call-iptables 之前,我们先来回顾下容器网络通信的基础知识。
基于网桥的容器网络#
Kubernetes 集群网络有很多种实现,有很大一部分都用到了 Linux 网桥:
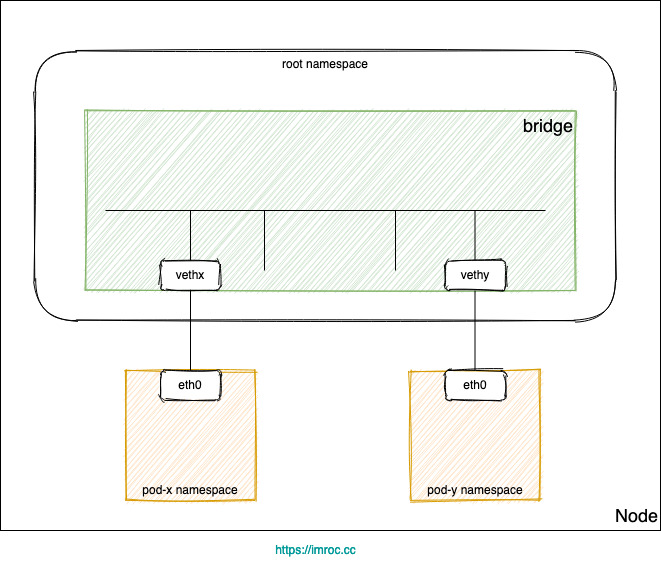
- 每个 Pod 的网卡都是 veth 设备,veth pair 的另一端连上宿主机上的网桥。
- 由于网桥是虚拟的二层设备,同节点的 Pod 之间通信直接走二层转发,跨节点通信才会经过宿主机 eth0。
Service 同节点通信问题#
不管是 iptables 还是 ipvs 转发模式,Kubernetes 中访问 Service 都会进行 DNAT,将原本访问 ClusterIP:Port 的数据包 DNAT 成 Service 的某个 Endpoint (PodIP:Port),然后内核将连接信息插入 conntrack 表以记录连接,目的端回包的时候内核从 conntrack 表匹配连接并反向 NAT,这样原路返回形成一个完整的连接链路:
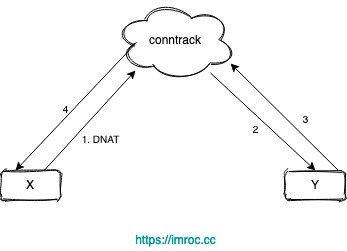
但是 Linux 网桥是一个虚拟的二层转发设备,而 iptables conntrack 是在三层上,所以如果直接访问同一网桥内的地址,就会直接走二层转发,不经过 conntrack:
Pod 访问 Service,目的 IP 是 Cluster IP,不是网桥内的地址,走三层转发,会被 DNAT 成 PodIP:Port。
如果 DNAT 后是转发到了同节点上的 Pod,目的 Pod 回包时发现目的 IP 在同一网桥上,就直接走二层转发了,没有调用 conntrack,导致回包时没有原路返回 (见下图)。
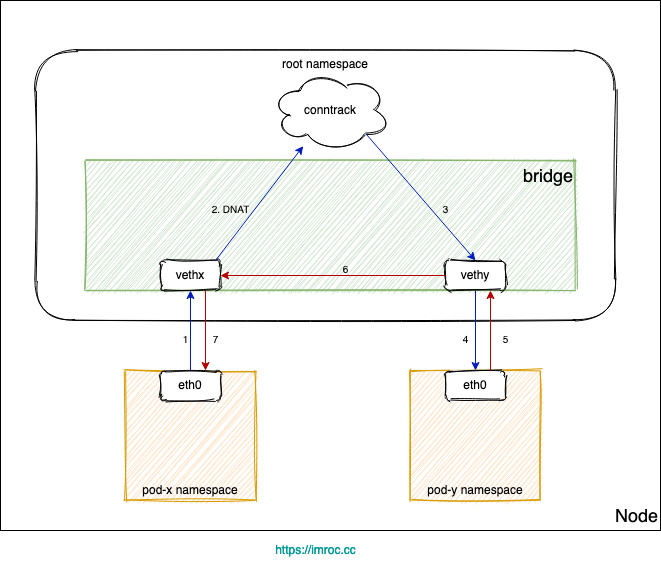
由于没有原路返回,客户端与服务端的通信就不在一个 “频道” 上,不认为处在同一个连接,也就无法正常通信。
开启 bridge-nf-call-iptables#
启用 bridge-nf-call-iptables 这个内核参数 (置为 1),表示 bridge 设备在二层转发时也去调用 iptables 配置的三层规则 (包含 conntrack),所以开启这个参数就能够解决上述 Service 同节点通信问题。
所以这里需要启用 bridge-nf-call-iptables :
$ modprobe br_netfilter
$ sysctl --write net.bridge.bridge-nf-call-iptables=1
现在再来测试一下连通性:
$ ip netns exec netns_leah curl 10.100.100.100:8080
终于成功了!
开启 Hairpin(发夹弯)模式#
虽然我们可以从网络命名空间 netns_leah 中通过虚拟服务成功访问另一个网络命名空间 netns_dustin 中的 HTTP 服务,但还没有测试过从 HTTP 服务所在的网络命名空间 netns_dustin 中直接通过虚拟服务访问自己,话不多说,直接测一把:
$ ip netns exec netns_dustin curl 10.100.100.100:8080
啊哈?竟然失败了,这又是哪里的问题呢?不要慌,开启 hairpin 模式就好了。那么什么是 hairpin 模式呢? 这是一个网络虚拟化技术中常提到的概念,也即交换机端口的VEPA模式。这种技术借助物理交换机解决了虚拟机间流量转发问题。很显然,这种情况下,源和目标都在一个方向,所以就是从哪里进从哪里出的模式。
怎么配置呢?非常简单,只需一条命令:
$ brctl hairpin bridge_home veth_dustin on
再次进行测试:
$ ip netns exec netns_dustin curl 10.100.100.100:8080
还是失败了。。。
然后我花了一个下午的时间,终于搞清楚了启用混杂模式后为什么还是不能解决这个问题,因为混杂模式和下面的选项要一起启用才能对 IPVS 生效:
$ sysctl --write net.ipv4.vs.conntrack=1
最后再测试一次:
$ ip netns exec netns_dustin curl 10.100.100.100:8080
这次终于成功了,但我还是不太明白为什么启用 conntrack 能解决这个问题,有知道的大神欢迎留言告诉我!
译者注:IPVS 及其负载均衡算法只针对首个数据包,后继的包必须被
conntrack表优先反转,如果没有conntrack,IPVS 对于回来的包是没有任何办法的。可以通过conntrack -L查看。
开启混杂模式#
如果想让所有的网络命名空间都能通过虚拟服务访问自己,就需要在连接到网桥的所有 veth 接口上开启 hairpin 模式,这也太麻烦了吧。有一个办法可以不用配置每个 veth 接口,那就是开启网桥的混杂模式。
什么是混杂模式呢?普通模式下网卡只接收发给本机的包(包括广播包)传递给上层程序,其它的包一律丢弃。混杂模式就是接收所有经过网卡的数据包,包括不是发给本机的包,即不验证MAC地址。
如果一个网桥开启了混杂模式,就等同于将所有连接到网桥上的端口(本文指的是 veth 接口)都启用了 hairpin 模式。可以通过以下命令来启用 bridge_home 的混杂模式:
$ ip link set bridge_home promisc on
现在即使你把 veth 接口的 hairpin 模式关闭:
$ brctl hairpin bridge_home veth_dustin off
仍然可以通过连通性测试:
$ ip netns exec netns_dustin curl 10.100.100.100:8080
优化 MASQUERADE#
在文章开头准备实验环境的章节,执行了这么一条命令:
$ iptables \
--table nat \
--append POSTROUTING \
--source 10.0.0.0/24 \
--jump MASQUERADE
这条 iptables 规则会对所有来自 10.0.0.0/24 的流量进行伪装。然而 Kubernetes 并不是这么做的,它为了提高性能,只对来自某些具体的 IP 的流量进行伪装。
为了更加完美地模拟 Kubernetes,我们继续改造规则,先把之前的规则删除:
$ iptables \
--table nat \
--delete POSTROUTING \
--source 10.0.0.0/24 \
--jump MASQUERADE
然后添加针对具体 IP 的规则:
$ iptables \
--table nat \
--append POSTROUTING \
--source 10.0.0.11/32 \
--jump MASQUERADE
果然,上面的所有测试都能通过。先别急着高兴,又有新问题了,现在只有两个网络命名空间,如果有很多个怎么办,每个网络命名空间都创建这样一条 iptables 规则?我用 IPVS 是为了啥?就是为了防止有大量的 iptables 规则拖垮性能啊,现在岂不是又绕回去了。
不慌,继续从 Kubernetes 身上学习,使用 ipset 来解决这个问题。先把之前的 iptables 规则删除:
$ iptables \
--table nat \
--delete POSTROUTING \
--source 10.0.0.11/32 \
--jump MASQUERADE
然后使用 ipset 创建一个集合 (set) :
$ ipset create DUSTIN-LOOP-BACK hash:ip,port,ip
这条命令创建了一个名为 DUSTIN-LOOP-BACK 的集合,它是一个 hashmap,里面存储了目标 IP、目标端口和源 IP。
接着向集合中添加条目:
$ ipset add DUSTIN-LOOP-BACK 10.0.0.11,tcp:8080,10.0.0.11
现在不管有多少网络命名空间,都只需要添加一条 iptables 规则:
$ iptables \
--table nat \
--append POSTROUTING \
--match set \
--match-set DUSTIN-LOOP-BACK dst,dst,src \
--jump MASQUERADE
网络连通性测试也没有问题:
$ curl 10.100.100.100:8080
$ ip netns exec netns_leah curl 10.100.100.100:8080
$ ip netns exec netns_dustin curl 10.100.100.100:8080
新增虚拟服务的后端#
最后,我们把网络命名空间 netns_leah 中的 HTTP 服务也添加到虚拟服务的后端:
$ ipvsadm \
--add-server \
--tcp-service 10.100.100.100:8080 \
--real-server 10.0.0.21:8080 \
--masquerading
再向 ipset 的集合 DUSTIN-LOOP-BACK 中添加一个条目:
$ ipset add DUSTIN-LOOP-BACK 10.0.0.21,tcp:8080,10.0.0.21
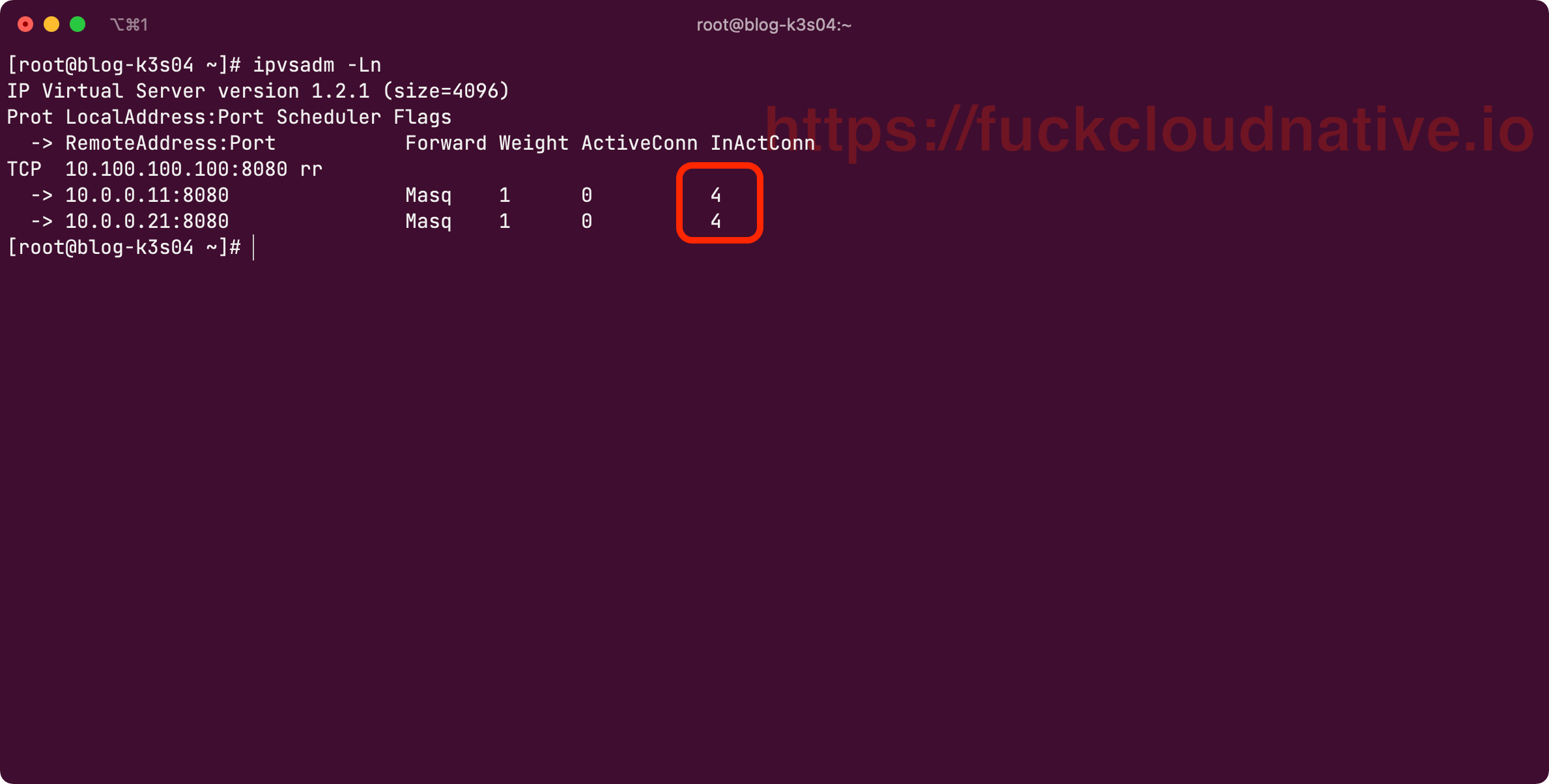
终极测试来了,试着多运行几次以下的测试命令:
$ curl 10.100.100.100:8080
你会发现轮询算法起作用了:
总结#
相信通过本文的实验和讲解,大家应该理解了 kube-proxy IPVS 模式的工作原理。在实验过程中,我们还用到了 ipset,它有助于解决在大规模集群中出现的 kube-proxy 性能问题。如果你对这篇文章有任何疑问,欢迎和我进行交流。