




集群成员变更一直是 etcd 最棘手的问题之一,在变更过程中会遇到各种各样的挑战,我们稍后一一来看。为了把问题描述清楚,首先需要了解 etcd 内部的 raft 实现。
etcd 内部的 raft 实现#
leader 会存储所有 follower 对自身 log 数据的 progress(复制进度),leader 根据每个 follower 的 progress 向其发送 replication message。
replication message 是 msgApp 外加上 log 数据。
progress 有两个比较重要的属性:match 和 next。match 是 leader 知道的 follower 对自身数据的最新复制进度【或者说就是 follower 最新的 log entry sent index】,如果 leader 对 follower 的复制进度一无所知则这个值为 0。next 则是将要发送给 follower 的下一个 log entry sent 的序号。
progress 有三个状态:probe,replicate 和 snapshot。
+--------------------------------------------------------+
| send snapshot |
| |
+---------+----------+ +----------v---------+
+---> probe | | snapshot |
| | max inflight = 1 <----------------------------------+ max inflight = 0 |
| +---------+----------+ +--------------------+
| | 1. snapshot success
| | (next=snapshot.index + 1)
| | 2. snapshot failure
| | (no change)
| | 3. receives msgAppResp(rej=false&&index>lastsnap.index)
| | (match=m.index,next=match+1)
receives msgAppResp(rej=true)
(next=match+1)| |
| |
| |
| | receives msgAppResp(rej=false&&index>match)
| | (match=m.index,next=match+1)
| |
| |
| |
| +---------v----------+
| | replicate |
+---+ max inflight = n |
+--------------------+
如果 follower 处于 probe 状态,则 leader 每个心跳包最多只发送一个 replication message。leader 会缓慢发送 replication message 并探测 follower 的处理速度。leader 收到 msgHeartbeatResp 或者收到 msgAppResp(其中 reject 值为 true)时,leader 会发送下 一个 replication message。
当 follower 给 leader 的 msgAppResp 的 reject 为 false 的时候,它会被置为 replicate 状态,reject 为 false 就意味着 follower 能够跟上 leader 的发送速度。leader 会启动 stream 方式向以求最快的方式向 follower 发送 replication message。当 follower 与 leader 之间的连接断连或者 follower 给 leader 回复的 msgAppResp 的 reject 为 true 时,就会被重新置为 probe 状态,leader 当然也会把 next 置为 match+1。
当 follower 处于 replicate 状态时,leader 会一次尽量多地把批量 replication message 发送给 follower,并把 next 取值为当前 log entry sent 的最大值,以让 follower 尽可能快地跟上 leader 的最新数据。
当 follower 的 log entry set 与 leader 的 log entry sent 相差甚巨的时候,leader 会把 follower 的状态置为 snapshot,然后以 msgSnap 请求方式向其发送 snapshot 数据,发送完后 leader 就等待 follower 直到超时或者成功或者失败或者连接中断。当 follower 接收完毕 snapshot 数据后,就会回到 probe 状态。
当 follower 处于 snapshot 状态时候,leader 不再发送 replication message 给 follower。
新当选的 leader 会把所有 follower 的 state 置为 probe,把 match 置为0,把 next 置为自身 log entry set 的最大值。
leader 与 follower 之间进行数据同步的时候,可以通过下面两个步骤进行流量控制:
- 限制 message 的 max size。这个值是可以通过相关参数进行限定的,限定后可以降低探测 follower 接收速度的成本;
- 当 follower 处于
replicate状态时候,限定每次批量发送消息的数目。leader 在网络层之上有一个发送 buffer,通过类似于 tcp 的发送窗口的算法动态调整 buffer 的大小,以防止 leader 由于发包过快导致 follower 大量地丢包,提高发送成功率。
snapshot,故名思议,是某个时间节点上系统状态的一个快照,保存的是此刻系统状态数据,以便于让用户可以恢复到系统任意时刻的状态。etcd-raft 中的 snapshot 代表了应用的状态数据,而执行 snapshot 的动作也就是将应用状态数据持久化存储,这样,在该 snapshot 之前的所有日志便成为无效数据,可以删除。
集群成员变更#
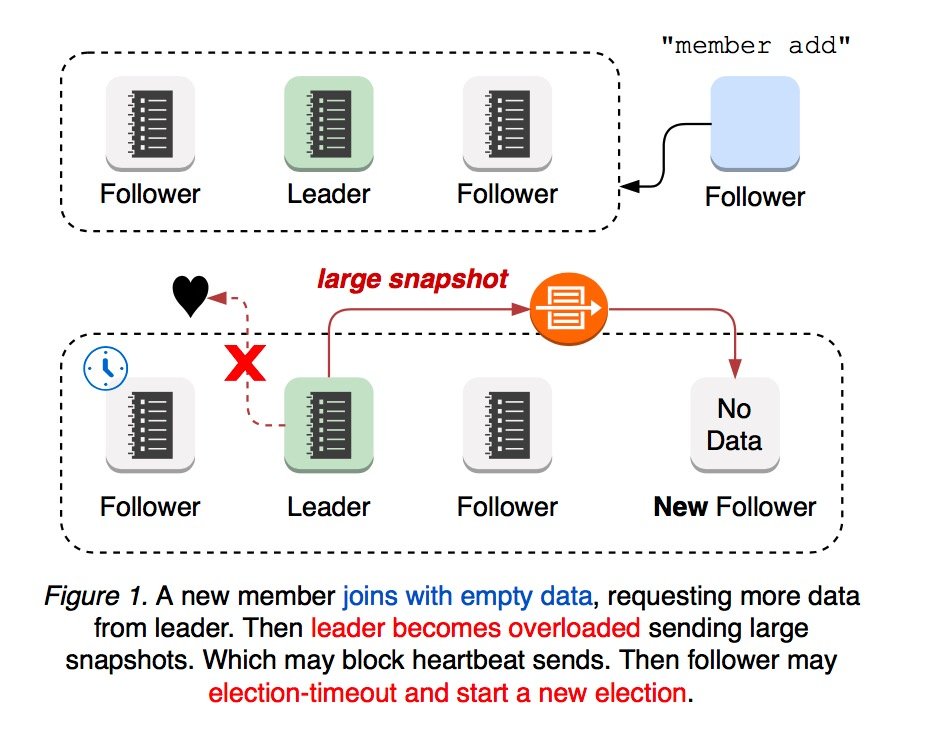
当集群加入新节点时,新加入的节点是没有任何数据的,因此新节点的 log entry sent 与 leader 的 log entry sent 相差很大,所以 leader 会向该节点发送 snapshot 数据。这时 leader 的网络有可能会过载、阻塞甚至丢弃 leader 发送给 follower 的 heartbeat,一段时间以后某个 follower 会因为选举超时将自己的状态切换为 candidate 并发起选举。所以新加入的节点很容易对集群造成影响,无论是 leader 选举还是将后续的更新传播给新成员,都很容易导致集群不可用。
网络隔离#
如果发生了网络隔离,集群还会正常工作吗?主要还是取决于 leader 被隔离到哪个区域。
当集群的 Leader 在多数节点这一侧时,集群仍可以正常工作。例如一个 3 节点集群,它的 quorum 为 2,其中一个 follower 被网络隔离,因为 leader 所在的这一侧的 majority 为 2,所以不会发生重新选举。
Quorum 机制,是一种分布式系统中常用的,用来保证数据冗余和最终一致性的投票算法,具体参考 分布式系统之 Quorum 机制。应用在 etcd 的场景中,quorum 表示能保证集群正常工作的最少节点数。而
majority表示集群当前能参加投票的节点数量。
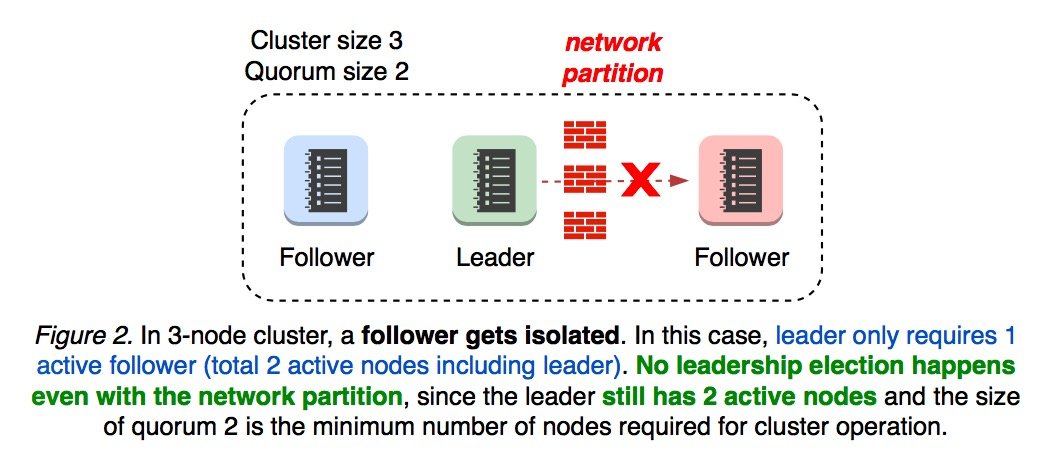
如果 leader 被整个集群都隔离了,这时 leader 的 majority 为 1,无法发起选举,leader 就会将自己的状态切换为 follower,影响到了集群的可用性。
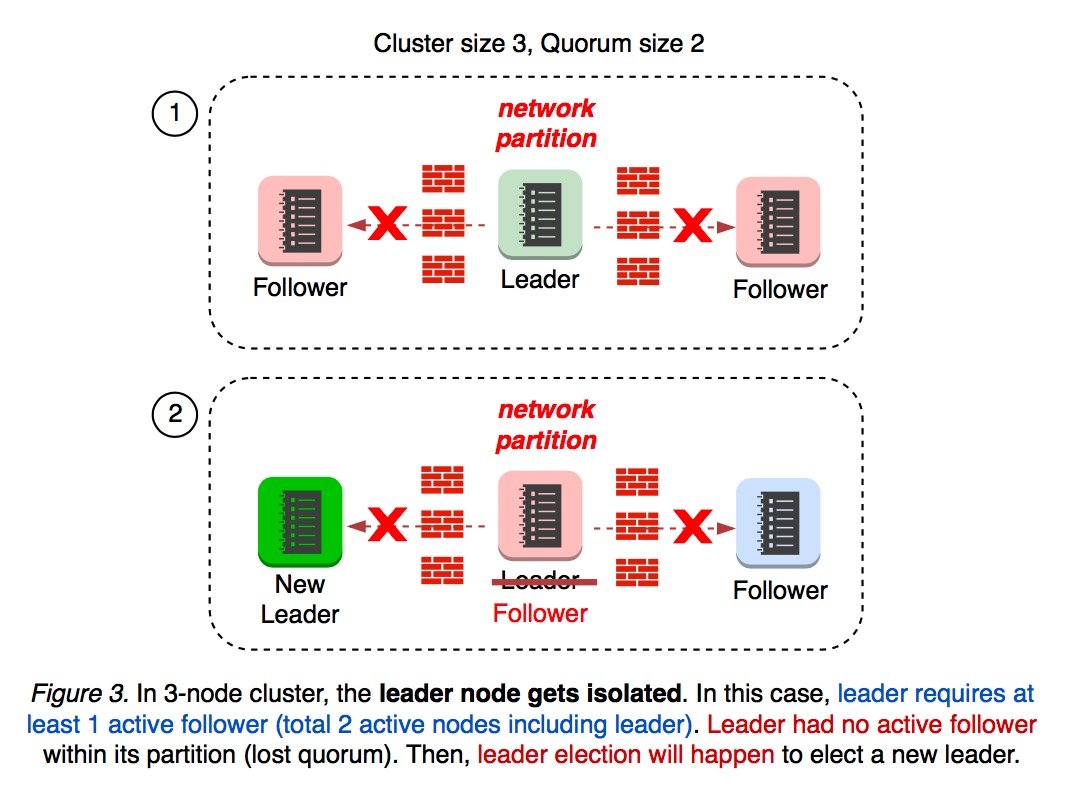
拥有 3 个节点的集群加入 1 个新节点之后集群节点数量变为 4,quorum 大小变为 3。
新加入节点后隔离网络#
如果加入新节点之后发生了网络隔离,集群还会正常工作吗?主要还是取决于新加入的节点被隔离到了哪个区域。
如果新加入的节点与 leader 被隔离在同一个区域内,leader 的 majority 数量仍然为 3,不会导致重新选举,也不会影响集群的可用性。
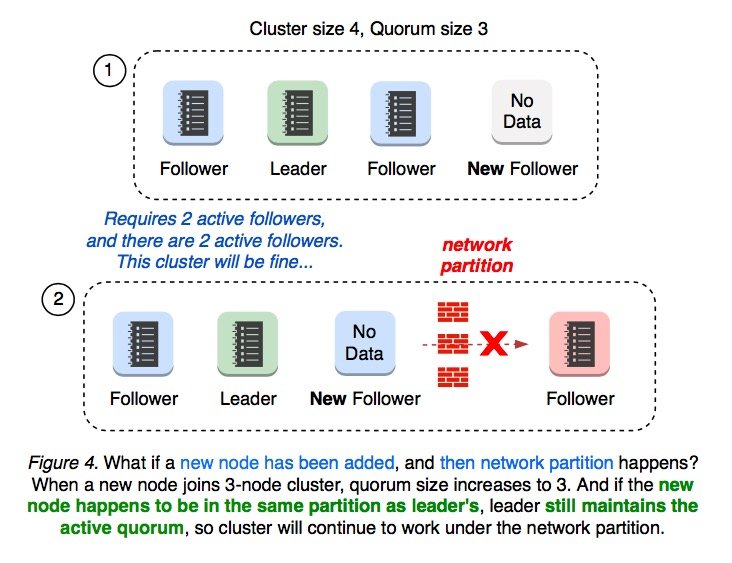
如果新节点与 leader 不在同一区域内,并且集群被对半隔离,这时任何一侧的 majority 都不是 3,从而会发生重新选举,leader 将状态切换为 follower。
隔离网络后再加入新节点#
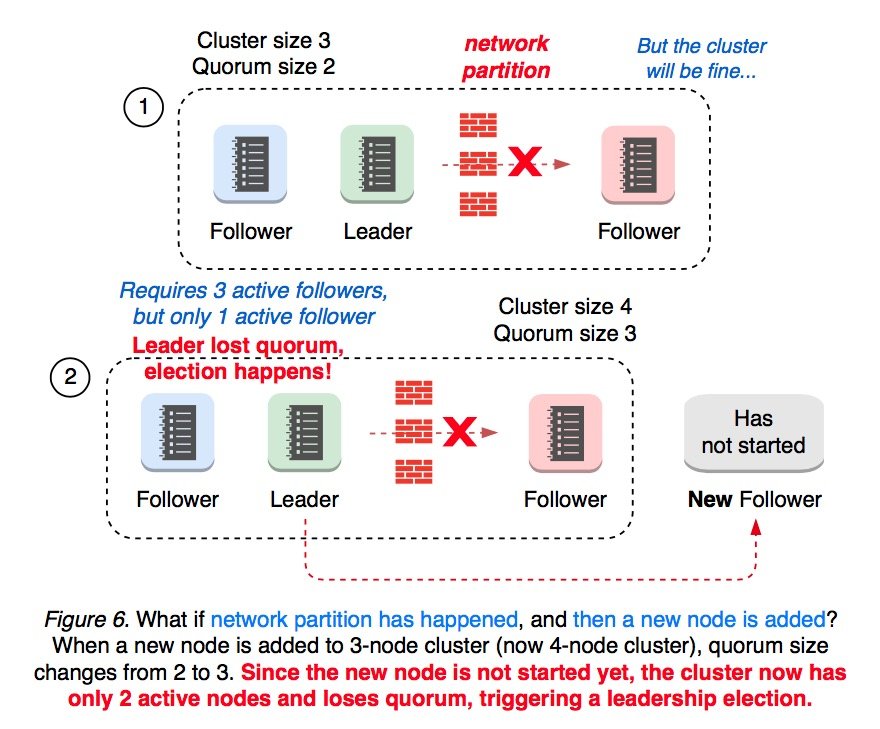
如果先发生网络隔离,后加入新节点,集群还会正常工作吗?
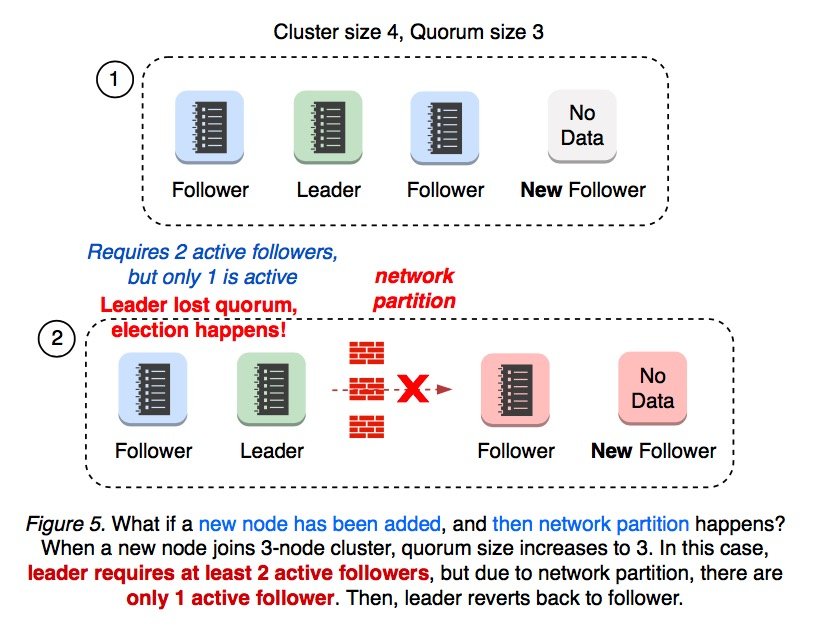
假设一个拥有 3 个节点的集群已经有一个 foloower 被隔离了,这时再加入新节点,quorum 就会从 2 变为 3。但此时新加入的节点还没有启动,集群的 majority 为 2,从而会发生重新选举。
因为 member add 命令会改变集群的 quorum 大小,所以建议先通过 member remove 命令移除处于崩溃状态的 follower。
加入新节点带来的问题#
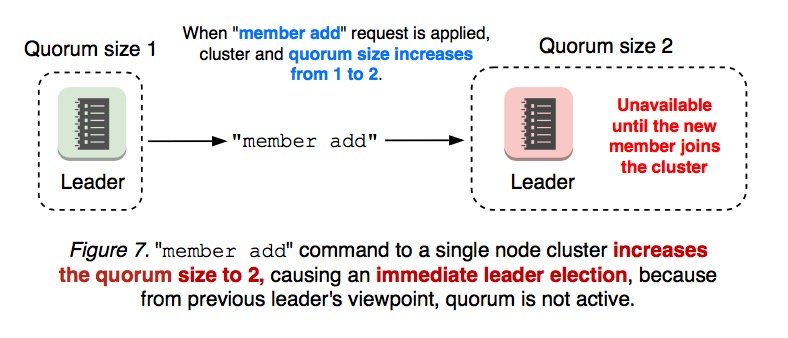
向一个单节点集群中加入新节点后,集群的 quorum 大小变为 2,但这时还会发生重新选举,为什么呢?因为加入节点的操作是分成两步进行的:
- 执行
member add命令 - 启动新节点
当你执行完 member add 命令后,集群的 quorum 大小变为 2,但此时新节点还没有启动,从 leader 的视角来看,majority 仍然是 1,不满足 quorum,所以会重新选举。
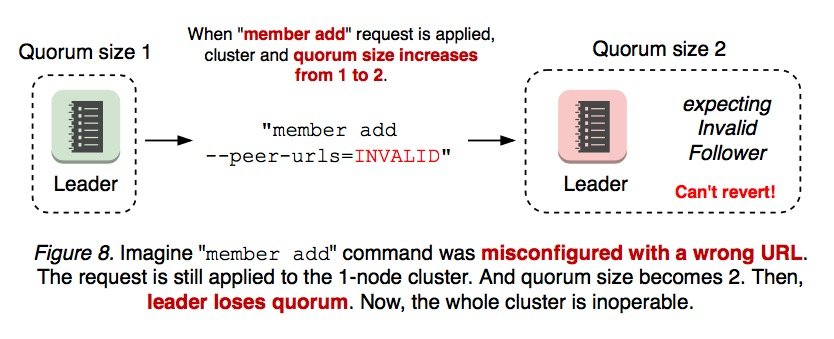
来看一种更糟糕的场景,如果新加入的节点配置错误(比如 --peer-urls 是非法的),当执行 member add 命令之后,单节点集群的 quorum 大小变为 2,发生重新选举,但此时新节点不会启动成功的,所以无法满足 quorum。一旦集群无法满足 quorum,就再也无法完成集群成员变更。
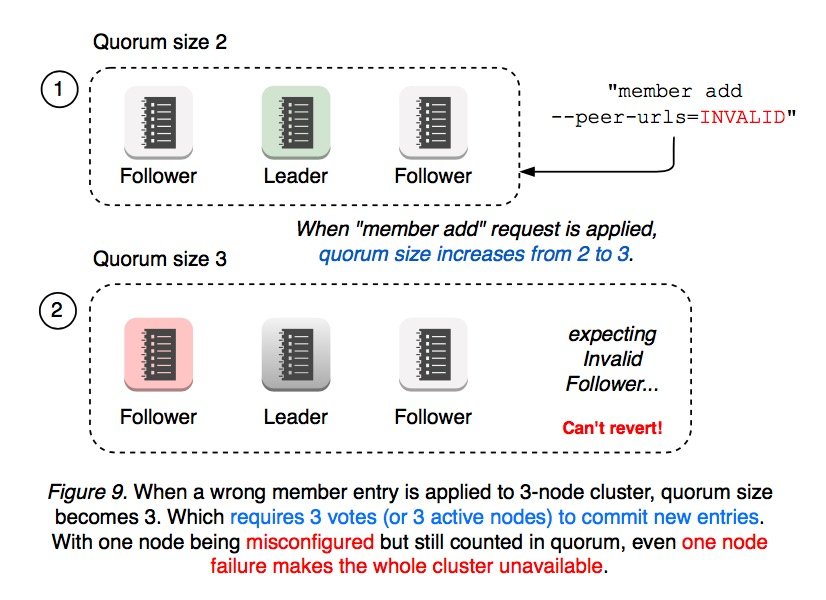
多节点集群类似。例如一个拥有 3 个节点的集群,新加入一个配置错误的节点后,quorum 大小从 2 变为 3。此时只要有 1 个 follower 发生故障,整个集群就会变为不可用状态,因为集群的 majority 为 2,不满足 quorum(其中 1 个 follower 发生故障,另一个配置错误)。
这就带来了一个很严峻的问题 :** 只要新加入的节点配置上出了点什么差错,整个集群的容错能力就会减 1。**这时你只能通过 etcd --force-new-cluster 命令来重新创建集群。
但 etcd 可是 Kubernetes 集群至关重要的组件啊,即使是最轻微的中断也可能会对用户的生产环境产生重大影响。怎样才能使成员变更的操作更安全呢?相对于其他方面来说,leader 选举对 etcd 集群的可用性有着至关重要的影响:有没有办法在集群成员变更的时候不改变集群的 quorum 大小?能否让新加入的节点处于备用的空闲状态,缓慢接收 leader 的 replication message,直到与 leader 保持同步?新加入的节点如果配置错误,有没有办法能让其回退?或者有没有更安全的办法来完成集群成员变更的操作(新加入节点配置错误不会导致集群的容错能力下降)?集群管理员新加入节点时需要关心网络协议吗?无论节点的位置在哪,无论是否发生网络隔离,有没有办法让用来加入新节点的 API 都可以正常工作?
引入 Raft Learner 角色#
为了解决上一节提到的加入新节点带来的容错能力下降的问题,
rfat 4.2.1 论文 中介绍了一种新的节点角色:Learner。以该角色加入集群的节点不参与投票选举,近接收 leader 的 replication message,直到与 leader 保持同步为止。
v3.4 中的新特性#
集群管理员向集群中添加新节点时要尽可能减少不必要的操作项。通过 member add --learner 命令可以向 etcd 集群中添加 learner 节点,不参加投票,只接收 replication message。
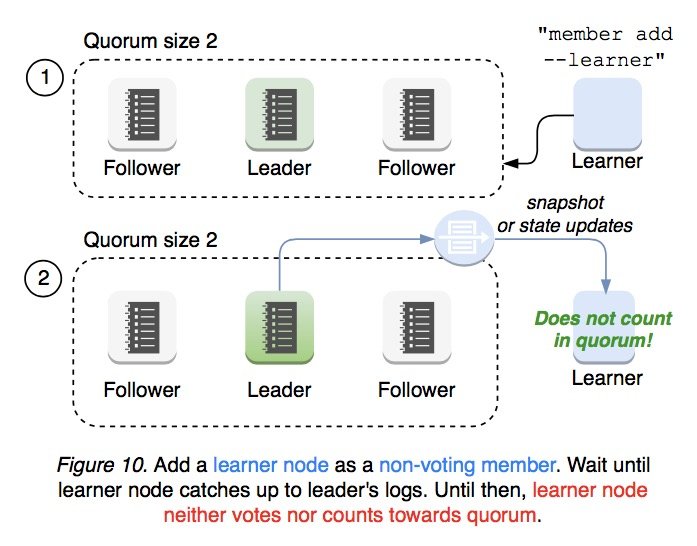
当 Learner 节点与 leader 保持同步之后,可以通过 member promote 来将该节点的状态提升为 follower,然后将其计入 quorum 的大小之中。
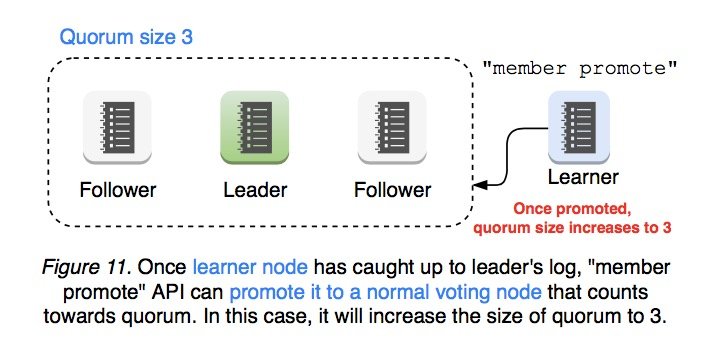
leader 会验证 promote 请求来确保其操作的安全性。只有当 learner 的 log 数据与 leader 保持一致后,learner 才能被提升为 follower 节点。

Learner 被提升为 follower 之前会一直被当成备用节点,且 leader 节点不能被转换为 learner 节点。learner 节点也不会接受客户端的读写操作,这就意味着 learner 不需要向 leader 发送 Read Index 请求。这种限制简化了 etcd v3.4 中 learner 的实现方式。
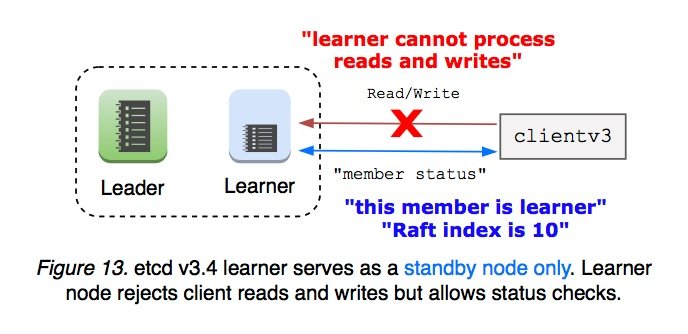
除此之外,etcd 还限制了集群中 Learner 节点数量的上限,以避免大量的 replication message 使 leader 过载。Learner 节点自身不能改变自己的状态,etcd 提供了 learner 状态检测和安全性检测,集群管理员必须自己决定要不要改变 learner 的状态。
v3.5 中的新特性#
- 新加入的节点默认就是 Learner 角色
- 当 learner 的 log 数据与 leader 保持一致后,集群会自动将 learner 转换为 follower。从用户的角度来看,你仍然可以使用
member add命令来加入新节点,但集群会自动帮你把新加入的节点设置为 learner 状态。 - 新加入的节点被视为备用节点,一旦集群的可用性受到影响,就会被提升为 follower 状态。
- learner 节点可以被设置为只读状态,被设置成只读状态后就永远不能被提升为 follower 状态。在弱一致性模式中,learner 只接收 leader 发送的数据,并且永远不会响应写操作。在没有共识开销的情况下从本地读取数据会大大减少 leader 的工作量,但向客户端提供的数据可能会过时。在强一致性模式中,learner 会向 leader 发送
read index以获取最新的数据,但仍然拒绝写请求。