





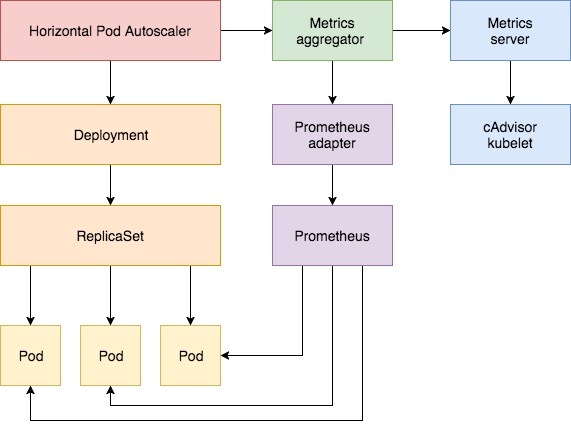
从 Kubernetes 1.8 开始,资源使用指标(如容器 CPU 和内存使用率)可以通过 Metrics API 在 Kubernetes 中获取。 这些指标可以直接被用户访问(例如通过使用 kubectl top 命令),或由集群中的控制器使用(例如,Horizontal Pod Autoscale 可以使用这些指标作出决策)。
例如,可以使用 kubectl top node 和 kubectl top pod 查看资源使用情况:
$ kubectl top node
NAME CPU(cores) CPU% MEMORY(bytes) MEMORY%
192.168.123.248 245m 12% 2687Mi 34%
192.168.123.249 442m 22% 3270Mi 42%
192.168.123.250 455m 22% 4014Mi 52%
$ kubectl top pod
NAME CPU(cores) MEMORY(bytes)
details-v1-64b86cd49-52g82 0m 11Mi
podinfo-6b86c8ccc9-5qr8b 0m 7Mi
podinfo-6b86c8ccc9-hlxm7 0m 12Mi
podinfo-6b86c8ccc9-qxhng 0m 6Mi
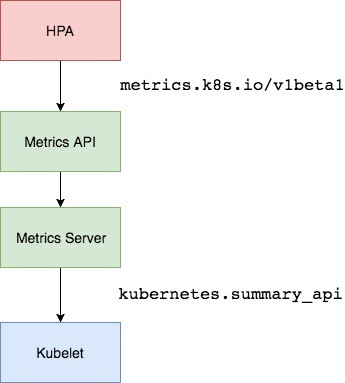
Resource Metrics API#
通过 Metrics API,您可以获取指定 node 或 pod 当前使用的资源量。这个 API 不存储指标值, 因此想要获取某个指定 node 10分钟前的资源使用量是不可能的。
Metrics API 和其他的 API 没有什么不同,它可以通过与 /apis/metrics.k8s.io/ 路径下的其他 Kubernetes API 相同的端点来发现,并且提供了相同的安全性、可扩展性和可靠性保证,Metrics API 在
k8s.io/metrics 仓库中定义,你可以在这里找到关于 Metrics API 的更多信息。
注意 : Metrics API 需要在集群中部署 Metrics Server。否则它将不可用。
Metrics Server#
Metrics Server 实现了Resource Metrics API。
Metrics Server 是集群范围资源使用数据的聚合器。 从 Kubernetes 1.8 开始,它作为一个 Deployment 对象默认部署在由 kube-up.sh 脚本创建的集群中。 如果你使用了其他的 Kubernetes 安装方法,您可以使用 Kubernetes 1.7+ (请参阅下面的详细信息) 中引入的 deployment yamls 文件来部署。
Metrics Server 从每个节点上的 Kubelet 公开的 Summary API 中采集指标信息。
通过在主 API server 中注册的 Metrics Server Kubernetes 聚合器 来采集指标信息, 这是在 Kubernetes 1.7 中引入的。在 设计文档 中可以了解到有关 Metrics Server 的更多信息。
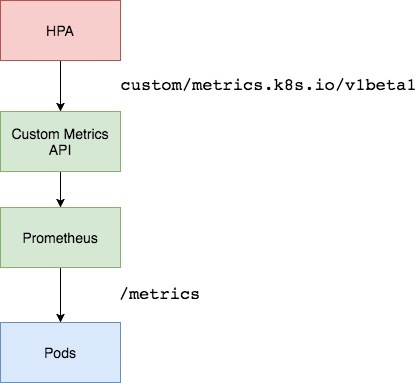
custom metrics api#
该 API 允许消费者访问通过任意指标描述的 Kubernetes 资源。如果你想实现这个 API Service,请参阅 kubernetes-incubator/custom-metrics-apiserver,这是一个用来实现 Kubernetes 自定义指标的框架。
HPA#
自动伸缩是一种根据资源使用情况自动伸缩工作负载的方法。自动伸缩在 Kubernetes 中有两个维度:
- Cluster Autoscaler : 用来处理节点扩容。
- Horizontal Pod Autoscaler : 自动缩放 rs 或 rc 中的 pod。
Cluster Autoscaler 和 Horizontal Pod Autoscaler 一起可用于动态调整集群的计算能力。虽然 Cluster Autoscaler 高度依赖于托管集群的云服务商提供的底层功能,但是 HPA 可以独立于你的 IaaS/PaaS 提供商进行操作。
Kubernetes 自 1.2 版本引入 HPA 机制,到 1.6 版本之前一直是通过 kubelet 来获取监控指标来判断是否需要扩缩容,1.6 版本之后必须通过 API server、Heapseter 或者 kube-aggregator 来获取监控指标。
Kubernetes 1.7 引入了聚合层,允许第三方应用程序通过注册为 API 附加组件来扩展 Kubernetes API。 自定义指标 API 以及聚合层使得像 Prometheus 这样的监控系统可以向 HPA 控制器公开针对特定应用程序的指标。
hpa 实现了一个控制环,可以周期性的从 Resource Metrics API 查询特定应用的 CPU 和内存信息。
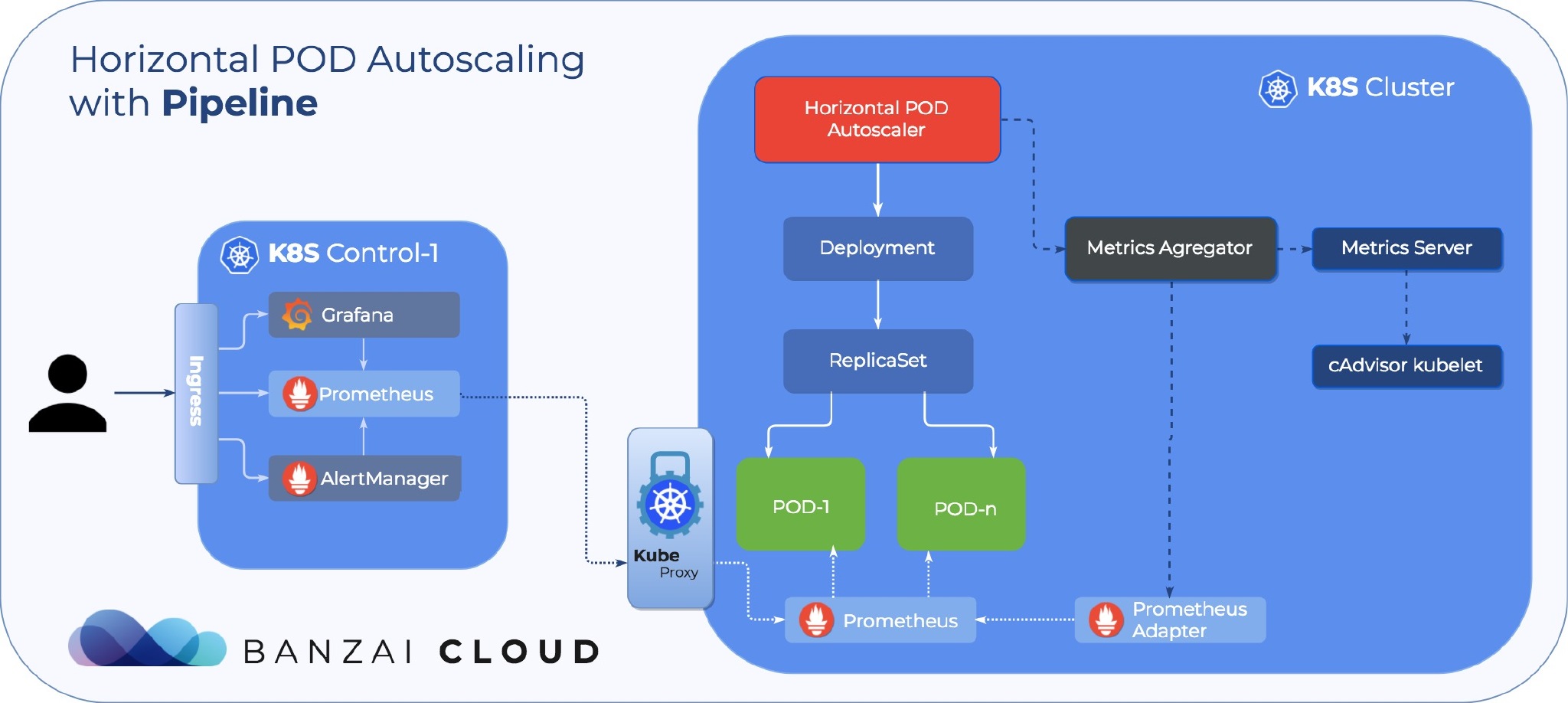
实战#
以下是一份为 Kubernetes 1.9 或更高版本配置 HPA v2 的分步指南。首先将会安装提供核心指标的 Metrics Server 附件组件,然后使用一个 demo 来演示基于 CPU 和内存使用的 Pod 的自动伸缩。在指南的第二部分,将会部署 Prometheus 和一个 custom metrics apiserver。聚合层会自动注册 custom metrics apiserver,然后通过一个 demo 来演示自定义指标的 HPA。
前提#
- 开启聚合层 API
- go 1.8+
- 克隆 k8s-prom-hpa 仓库
$ cd $GOPATH
$ git clone https://github.com/stefanprodan/k8s-prom-hpa
安装 Metrics Server#
Kubernetes Metrics Server 是一个集群范围内的资源使用量的聚合器,它是 Heapster 的继承者。Metrics Server 通过汇集来自 kubernetes.summary_api 的数据来收集 node 和 pod 的 CPU 和内存使用情况。summary API 是用于将数据从 Kubelet/cAdvisor 传递到 Metrics Server 的高效内存 API。
在安装 Metrics Server 之前需要先进行如下配置:
- 将 kube-controller-manager 的启动参数
--horizontal-pod-autoscaler-use-rest-clients的值设置为 true。 - 在 kube-controller-manager 的启动参数 –master 设置为 kube-apiserver 的地址,如:
--master=http://172.20.0.113:8080。
在 kube-system 命名空间部署 metrics-server:
$ kubectl create -f ./metrics-server
一分钟后,度量服务器开始报告节点和 Pod 的 CPU 和内存使用情况。 查看 nodes 指标:
$ kubectl get --raw "/apis/metrics.k8s.io/v1beta1/nodes" | jq .
查看 pods 指标:
$ kubectl get --raw "/apis/metrics.k8s.io/v1beta1/pods" | jq .
基于 CPU 和内存使用的自动缩放#
下面使用一个基于 golang 的小程序来测试 HPA。
在 default 命名空间中部署 podinfo:
$ kubectl create -f ./podinfo/podinfo-svc.yaml,./podinfo/podinfo-dep.yaml
可以通过 http://PODINFO_SVC_IP:9898 来访问 podinfo。
接下来定义一个保持最少两个副本的 HPA,如果 CPU 平均使用量超过 80% 或内存超过 200Mi,则最高可扩展到 10 个副本:
apiVersion: autoscaling/v2beta1
kind: HorizontalPodAutoscaler
metadata:
name: podinfo
spec:
scaleTargetRef:
apiVersion: extensions/v1beta1
kind: Deployment
name: podinfo
minReplicas: 2
maxReplicas: 10
metrics:
- type: Resource
resource:
name: cpu
targetAverageUtilization: 80
- type: Resource
resource:
name: memory
targetAverageValue: 200Mi
创建 HPA:
$ kubectl create -f ./podinfo/podinfo-hpa.yaml
几秒钟之后,HPA 控制器与 metrics server 进行通信,然后获取 CPU 和内存使用情况。
$ kubectl get hpa
NAME REFERENCE TARGETS MINPODS MAXPODS REPLICAS AGE
podinfo Deployment/podinfo 2826240 / 200Mi, 15% / 80% 2 10 2 5m
为了提高 CPU 使用率、运行 rakyll/hey 进行压力测试:
#install hey
$ go get -u github.com/rakyll/hey
#do 10K requests
hey -n 10000 -q 10 -c 5 http://PODINFO_SVC_IP:9898/
你可以通过以下命令获取 HPA event:
$ kubectl describe hpa podinfo
Events:
Type Reason Age From Message
---- ------ ---- ---- -------
Normal SuccessfulRescale 7m horizontal-pod-autoscaler New size: 4; reason: cpu resource utilization (percentage of request) above target
Normal SuccessfulRescale 3m horizontal-pod-autoscaler New size: 8; reason: cpu resource utilization (percentage of request) above target
先将 podinfo 删除,稍后将会重新部署:
$ kubectl delete -f ./podinfo/podinfo-hpa.yaml,./podinfo/podinfo-dep.yaml,./podinfo/podinfo-svc.yaml
安装 Custom Metrics Server#
为了让 HPA 可以根据 custom metrics 进行扩展,你需要有两个组件:
- Prometheus : 从应用程序中收集指标并将其存储为 Prometheus 时间序列数据库。
- custom-metrics-apiserver : 使用 k8s-prometheus-adapter 提供的 metrics 来扩展 Kubernetes 自定义指标 API。
创建 monitoring 命名空间:
$ kubectl create -f ./namespaces.yaml
将 Prometheus v2 部署到 monitoring 命名空间:
$ kubectl create -f ./prometheus
生成 Prometheus adapter 所需的 TLS 证书:
$ make certs
部署 custom-metrics-apiserver:
$ kubectl create -f ./custom-metrics-api
列出由 Prometheus 提供的自定义指标:
$ kubectl get --raw "/apis/custom.metrics.k8s.io/v1beta1" | jq .
获取 monitoring 命名空间中所有 pod 的 FS 信息:
$ kubectl get --raw "/apis/custom.metrics.k8s.io/v1beta1/namespaces/monitoring/pods/*/fs_usage_bytes" | jq .
基于自定义指标的自动扩容#
在 default 命名空间中部署 podinfo:
$ kubectl create -f ./podinfo/podinfo-svc.yaml,./podinfo/podinfo-dep.yaml
podinfo 应用暴露了一个自定义的度量指标:http_requests_total。Prometheus adapter(即 custom-metrics-apiserver)删除了 _total 后缀并将该指标标记为 counter metric。
从自定义指标 API 获取每秒的总请求数:
$ kubectl get --raw "/apis/custom.metrics.k8s.io/v1beta1/namespaces/default/pods/*/http_requests" | jq .
{
"kind": "MetricValueList",
"apiVersion": "custom.metrics.k8s.io/v1beta1",
"metadata": {
"selfLink": "/apis/custom.metrics.k8s.io/v1beta1/namespaces/default/pods/%2A/http_requests"
},
"items": [
{
"describedObject": {
"kind": "Pod",
"namespace": "default",
"name": "podinfo-6b86c8ccc9-kv5g9",
"apiVersion": "/__internal"
},
"metricName": "http_requests",
"timestamp": "2018-01-10T16:49:07Z",
"value": "901m"
},
{
"describedObject": {
"kind": "Pod",
"namespace": "default",
"name": "podinfo-6b86c8ccc9-nm7bl",
"apiVersion": "/__internal"
},
"metricName": "http_requests",
"timestamp": "2018-01-10T16:49:07Z",
"value": "898m"
}
]
}
m 表示 毫,例如,901m 表示 901 毫次/每秒。
创建一个 HPA,如果请求数超过每秒 10 次将扩大 podinfo 副本数:
apiVersion: autoscaling/v2beta1
kind: HorizontalPodAutoscaler
metadata:
name: podinfo
spec:
scaleTargetRef:
apiVersion: extensions/v1beta1
kind: Deployment
name: podinfo
minReplicas: 2
maxReplicas: 10
metrics:
- type: Pods
pods:
metricName: http_requests
targetAverageValue: 10
在 default 命名空间部署 podinfo HPA:
$ kubectl create -f ./podinfo/podinfo-hpa-custom.yaml
几秒钟后 HPA 从 metrics API 获取 http_requests 的值:
$ kubectl get hpa
NAME REFERENCE TARGETS MINPODS MAXPODS REPLICAS AGE
podinfo Deployment/podinfo 899m / 10 2 10 2 1m
以每秒 25 个请求数的速度给 podinfo 加压:
#install hey
$ go get -u github.com/rakyll/hey
#do 10K requests rate limited at 25 QPS
$ hey -n 10000 -q 5 -c 5 http://PODINFO_SVC_IP:9898/healthz
几分钟后,HPA 开始扩大 podinfo 的副本数:
$ kubectl describe hpa podinfo
Name: podinfo
Namespace: default
Reference: Deployment/podinfo
Metrics: ( current / target )
"http_requests" on pods: 9059m / 10
Min replicas: 2
Max replicas: 10
Events:
Type Reason Age From Message
---- ------ ---- ---- -------
Normal SuccessfulRescale 2m horizontal-pod-autoscaler New size: 3; reason: pods metric http_requests above target
以目前的请求速度,podinfo 的副本数永远不会扩展到最大值,三个副本足以让每个 Pod 的请求速度保持在每秒 10 次以下。
停止加压后,HPA 会将副本数缩减成最小值:
Events:
Type Reason Age From Message
---- ------ ---- ---- -------
Normal SuccessfulRescale 5m horizontal-pod-autoscaler New size: 3; reason: pods metric http_requests above target
Normal SuccessfulRescale 21s horizontal-pod-autoscaler New size: 2; reason: All metrics below target
总结#
并非所有的系统都可以仅依靠 CPU 和内存指标来满足 SLA,大多数 Web 应用的后端都需要基于每秒的请求数量进行弹性伸缩来处理突发流量。对于 ETL 应用程序,可以通过设置 Job 队列长度超过某个阈值来触发弹性伸缩。通过 Prometheus 来监控应用程序并暴露出用于弹性伸缩的指标,可以微调应用程序以更好地处理突发事件,从而确保其高可用性。
参考#
