




现在我们都说设计可并行、高并发的程序,而且我们很多时候会在潜意识里觉得自己对并行(Parallelism)和并发(Concurrency)的区别很清楚,但如果要明确的说出二者的区别,又感觉没办法给出一个非常清晰的描述。
那么什么是并发?什么又是并行呢?并行的概念比较简单,并行总是和执行(executions)相关,很多东西同时执行就是并行;而并发则是通过一些方式组织你的程序,让它可以分成多个模块去独立的执行。并行必然是需要多核的,一个处理器是无法并行的;但并发和处理器并没有什么必然联系,在一个处理器上面,我们的程序也可以是并发的。
举个简单的例子,华罗庚泡茶,必须有烧水、洗杯子、拿茶叶等步骤。现在我们想尽快做完这件事,也就是“一共要处理很多事情”,有很多方法可以实现并发,例如请多个人同时做,这就是并行。并行是实现并发的一种方式,但不是唯一的方式。我们一个人也可以实现并发,例如先烧水、然后不用等水烧开就去洗杯子,所以通过调整程序运行方式也可以实现并发。
如果你觉得以上的讲解还是太抽象了,下面通过一个小故事来讲解,故事原型来自 Go 语言创始人之一 Rob Pike 的一篇演讲。
故事的开始有一个需求:有一群地鼠要把一堆废弃的说明书用小推车推到火炉去烧毁。
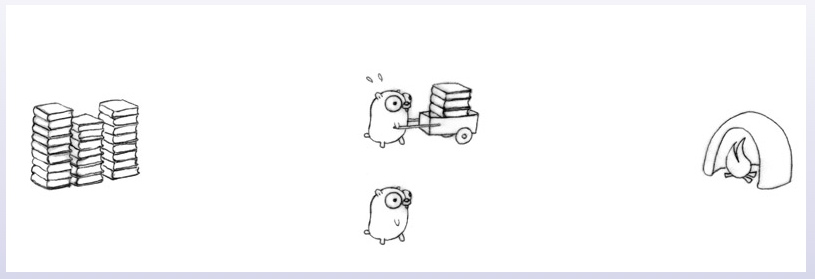
刚开始只有一只地鼠,使用一辆推车,将书装到车上,运输到火炉旁,将书卸到火炉。完成任务必然需要比较长的时间。

此时如果再增加一只地鼠,那也没什么用,因为一只地鼠在干活,另一只地鼠只能等待。(当然有人说两只地鼠轮流使用一辆推车,这样可以让地鼠得到休息,这样它们干活更快,也可以提高效率。)
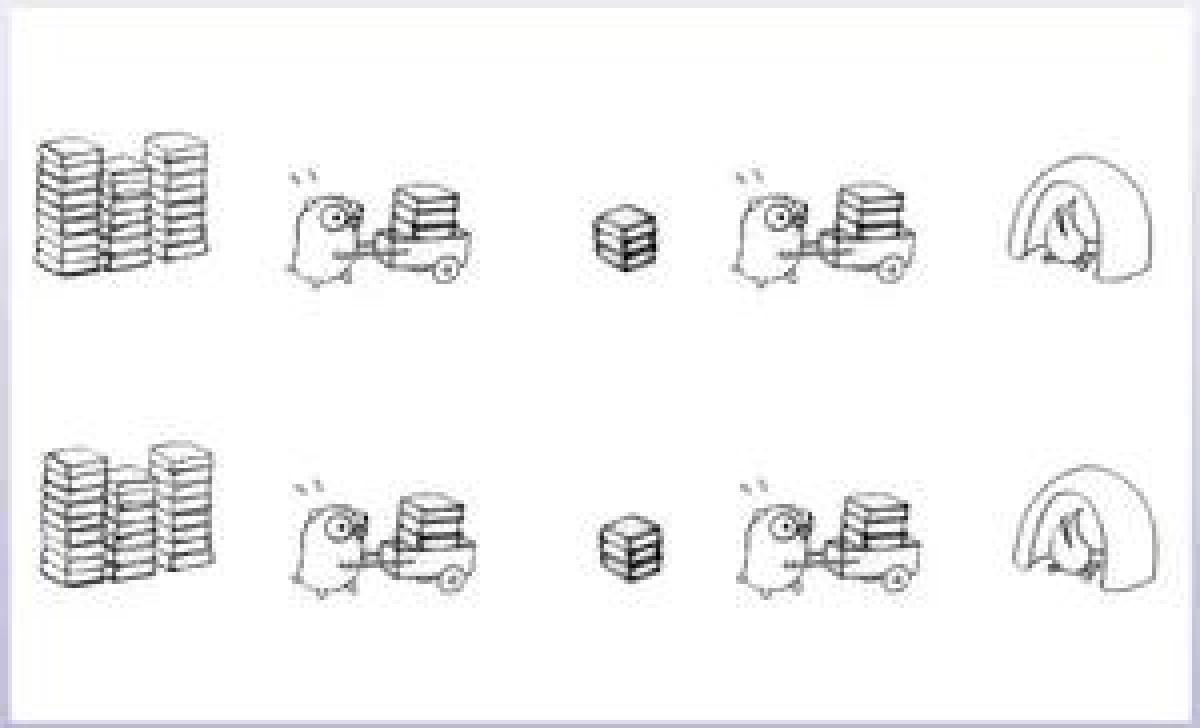
再找一辆推车来,两只地鼠分别使用各自的推车,将书装到车上,运输到火炉旁,将书卸到火炉。这样会提高运输效率,但它们会在装书和卸书时进行排队,降低了效率。
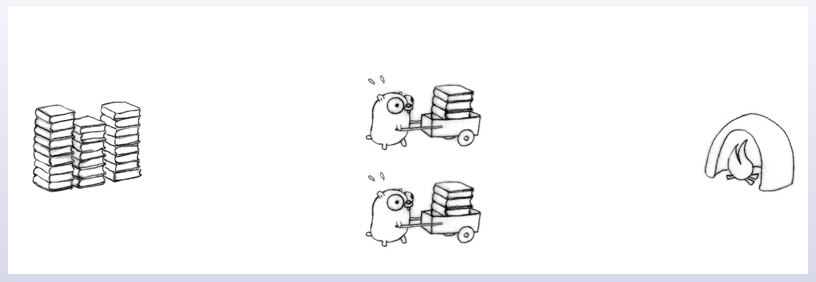
这样虽然比之前快了,但还是有瓶颈的。因为书只有一堆,火炉也只有一个,所以我们还必须通过消息来协调两只地鼠的行动。好吧,那我们再把书分成两堆,再增加一个火炉。
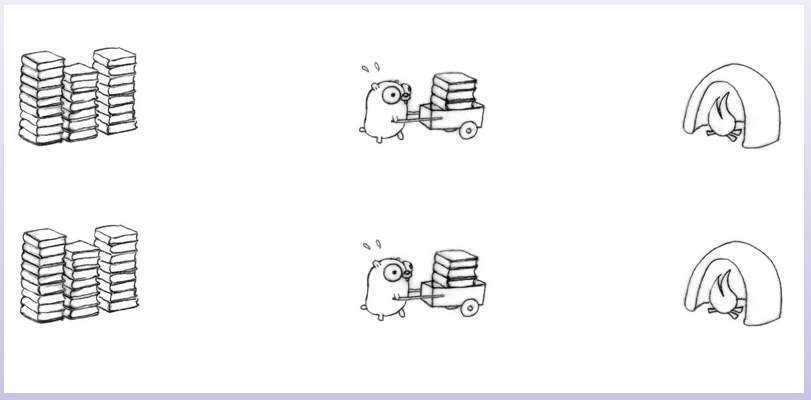
这样就比之前的效率高差不多一倍了。现在这个模型就是并发的,因为两只地鼠可以独立完成一件事了,这样提高了运输效率,而且在装书和卸书时不会进行排队,提高了装卸的效率。但这个模型不一定是并行的,比如同一时刻可能只有一只地鼠在干活。
上面就是第一种并发模型,我们还可以设计更多的并发模型,继续看漫画。
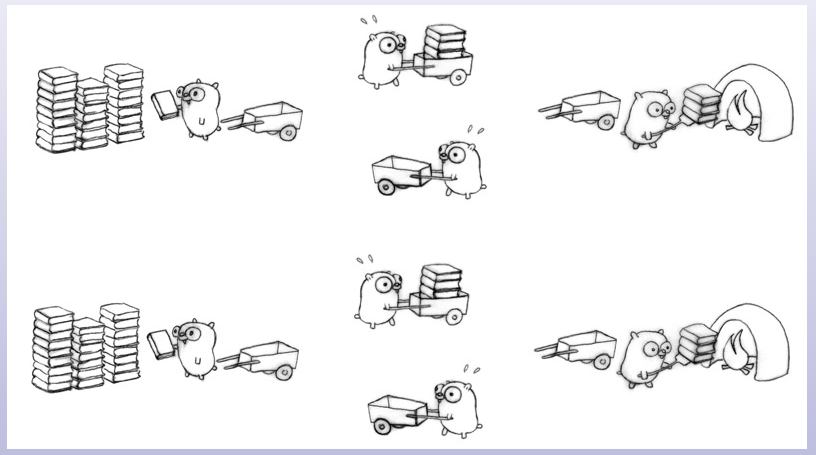
这次找了 3 只地鼠,一只负责把书装到车上,一只负责运输,一只负责把书卸到火炉焚烧。每只地鼠做一个独立的任务,当然三只地鼠之间需要使用一些诸如消息通信之类的手段进行协调。
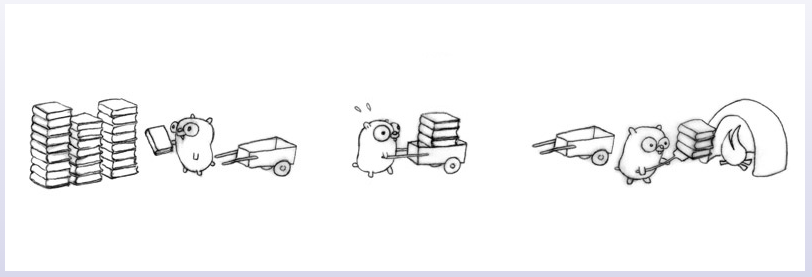
装书和烧书的两只地鼠都很轻松,负责运输的这只地鼠却很累,系统出现了瓶颈。那我们再找一只地鼠来,专门负责运回空推车。
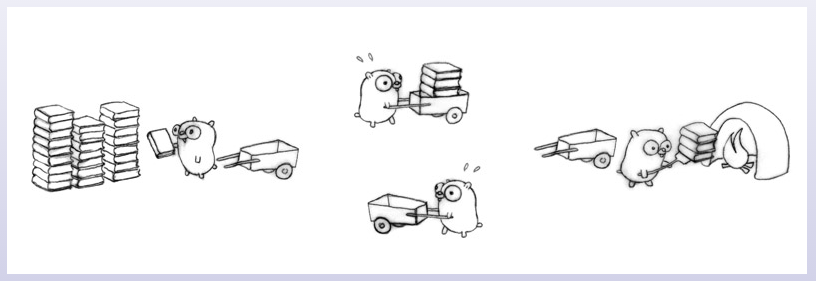
我们在一个已有的设计(指三个地鼠的那个设计)中添加一个并发的步骤(第四只地鼠)增强了系统的性能。这样一来,两只地鼠去搞运输,如果协调的好,理论情况下工作效率将是一只地鼠的 4 倍。
总共有 4 个并发的步骤:
- 把书装到车上;
- 把推车运到火炉旁;
- 把书卸到火炉里;
- 运回空推车。
可以再增加一个分组,将这个并发模型并行化。
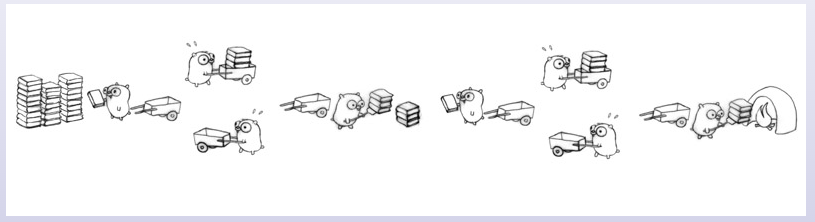
下面我们再来看另外一种并发模型。负责运输的地鼠抱怨说运输路程太长,那我们就增加一个中转站。

然后再增加一个分组,将这个并发模型并行化,两个分组并行执行。
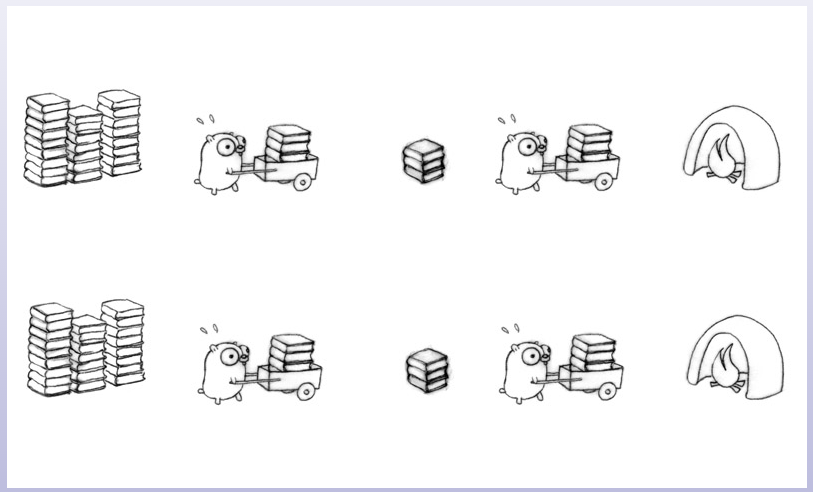
可以把上面的并发模型再改进一下。增加中转站的同时,再增加两只地鼠,一只负责将从书堆运过来的书卸到中转站,另一只负责将书从中转站装到推车里,再让后面的地鼠运输到火炉旁。
然后再增加一个分组,将这个并发模型并行化。
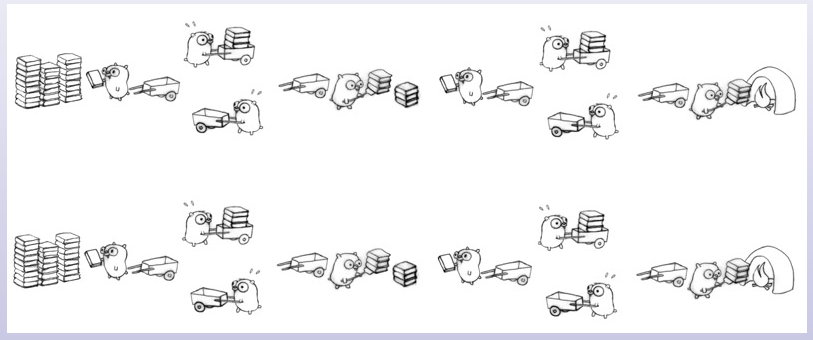
漫画到这里就结束了,总共介绍了三种并发模型,每种模型都可以很容易地并行化。可以看到上面的并发模型每改进一次,其实就是将任务拆的更细了,一旦分解了问题,并发就自然而然产生了,每个人只专注于一个任务。
回到程序中,书就代表着数据,地鼠就是 CPU,而车可能就是序列化、反序列化、网络等设施,火炉就是代理、浏览器或其他的消费者。而上面的并发模型就是一个可扩展的 Web Service。
该演讲题目为 《Concurrency is not Parallelism》 ,原文链接:
- 演讲幻灯片: https://talks.golang.org/2012/waza.slide
- 演讲视频:
参考链接