




Promtheus 本身只支持单机部署,没有自带支持集群部署,也不支持高可用以及水平扩容,它的存储空间受限于本地磁盘的容量。同时随着数据采集量的增加,单台 Prometheus 实例能够处理的时间序列数会达到瓶颈,这时 CPU 和内存都会升高,一般内存先达到瓶颈,主要原因有:
- Prometheus 的内存消耗主要是因为每隔 2 小时做一个
Block数据落盘,落盘之前所有数据都在内存里面,因此和采集量有关。 - 加载历史数据时,是从磁盘到内存的,查询范围越大,内存越大。这里面有一定的优化空间。
- 一些不合理的查询条件也会加大内存,如
Group或大范围Rate。
这个时候要么加内存,要么通过集群分片来减少每个实例需要采集的指标。本文就来讨论通过 Prometheus Operator 部署的 Prometheus 如何根据服务维度来拆分实例。
1. 根据服务维度拆分 Prometheus#
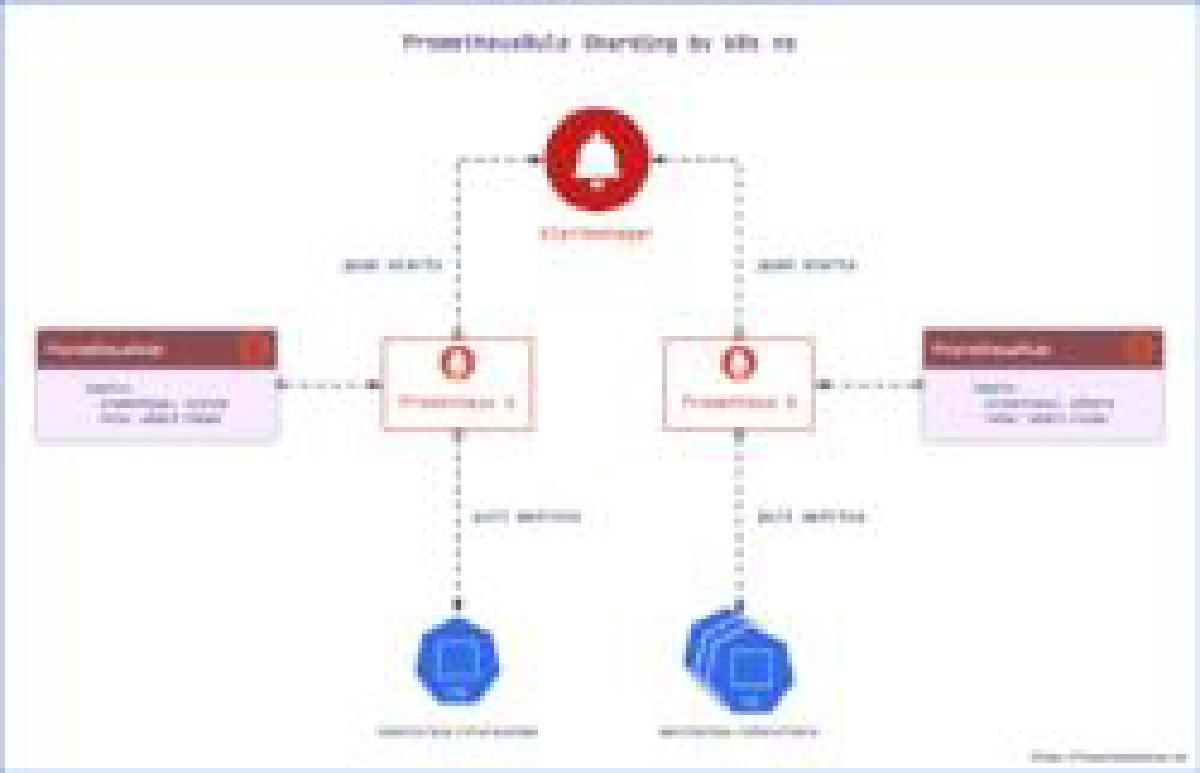
Prometheus 主张根据功能或服务维度进行拆分,即如果要采集的服务比较多,一个 Prometheus 实例就配置成仅采集和存储某一个或某一部分服务的指标,这样根据要采集的服务将 Prometheus 拆分成多个实例分别去采集,也能一定程度上达到水平扩容的目的。
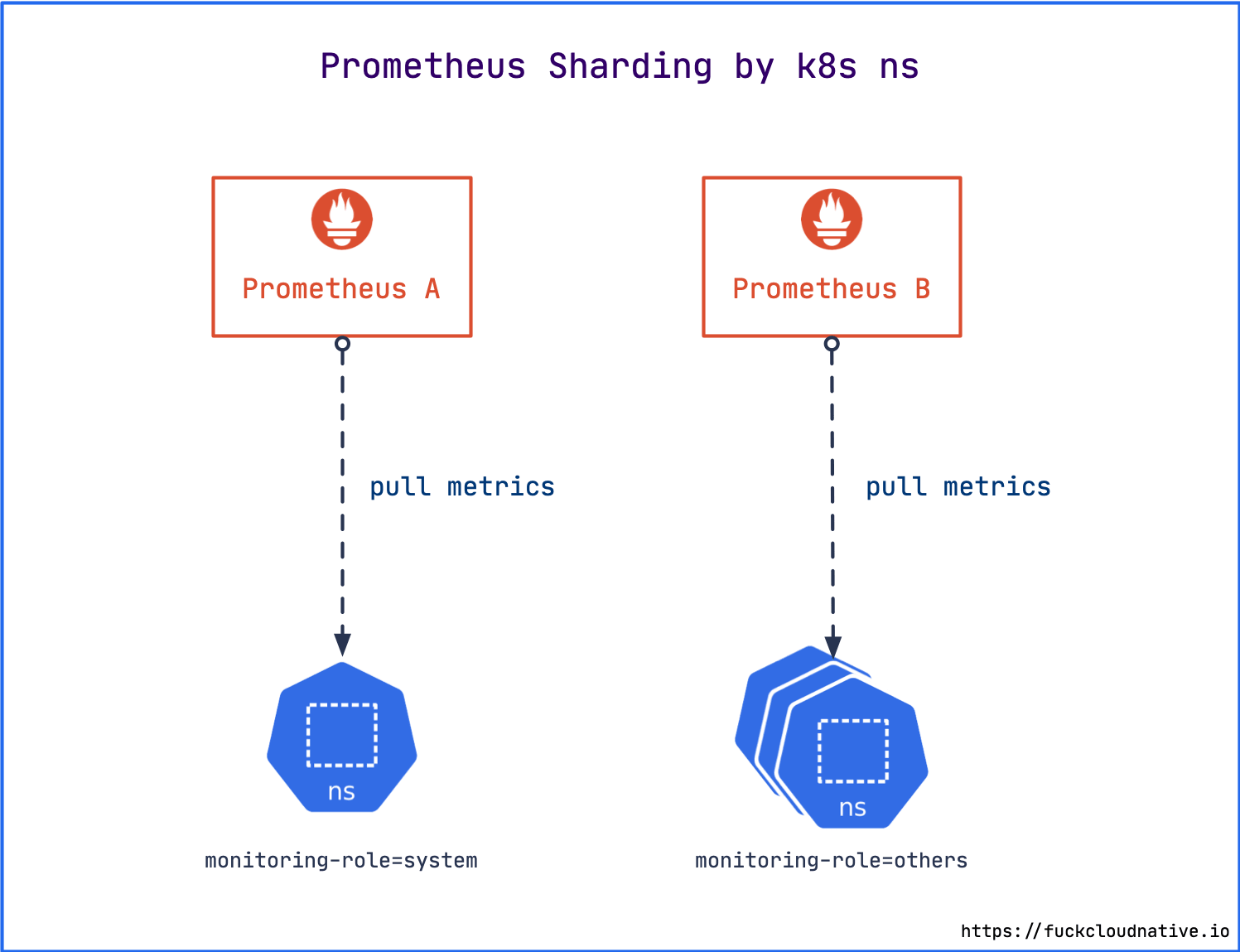
在 Kubernetes 集群中,我们可以根据 namespace 来拆分 Prometheus 实例,例如将所有 Kubernetes 集群组件相关的监控发送到一个 Prometheus 实例,将其他所有监控发送到另一个 Prometheus 实例。
Prometheus Operator 通过 CRD 资源名 Prometheus 来控制 Prometheus 实例的部署,其中可以通过在配置项 serviceMonitorNamespaceSelector 和 podMonitorNamespaceSelector 中指定标签来限定抓取 target 的 namespace。例如,将 namespace kube-system 打上标签 monitoring-role=system,将其他的 namespace 打上标签 monitoring-role=others。
2. 告警规则拆分#
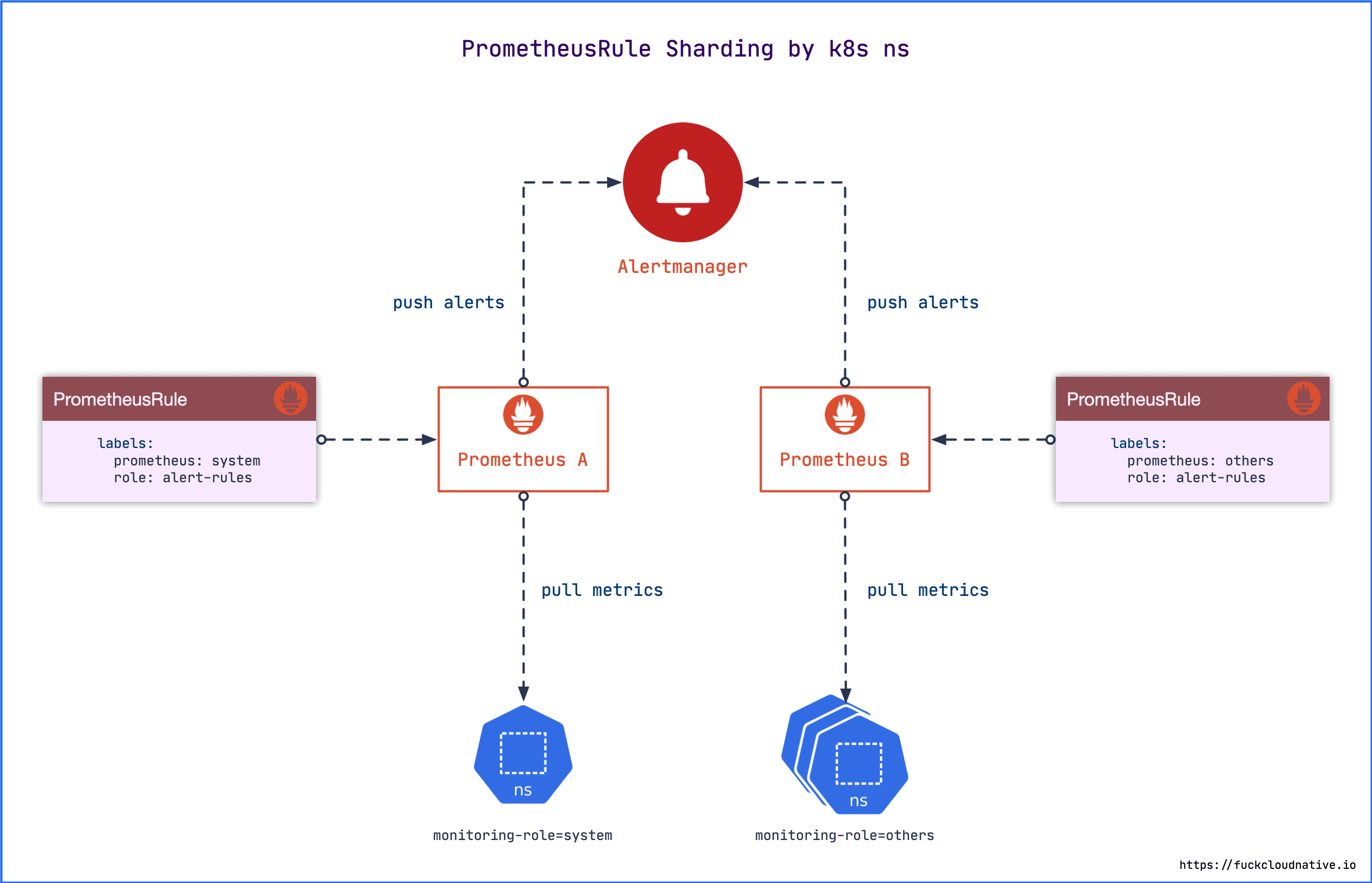
将 Prometheus 拆分成多个实例之后,就不能再使用默认的告警规则了,因为默认的告警规则是针对所有 target 的监控指标的,每一个 Prometheus 实例都无法获取所有 target 的监控指标,势必会一直报警。为了解决这个问题,需要对告警规则进行拆分,使其与每个 Prometheus 实例的服务维度一一对应,按照上文的拆分逻辑,这里只需要拆分成两个告警规则,打上不同的标签,然后在 CRD 资源 Prometheus 中通过配置项 ruleSelector 指定规则标签来选择相应的告警规则。
3. 集中数据存储#
解决了告警问题之后,还有一个问题,现在监控数据比较分散,使用 Grafana 查询监控数据时我们也需要添加许多数据源,而且不同数据源之间的数据还不能聚合查询,监控页面也看不到全局的视图,造成查询混乱的局面。
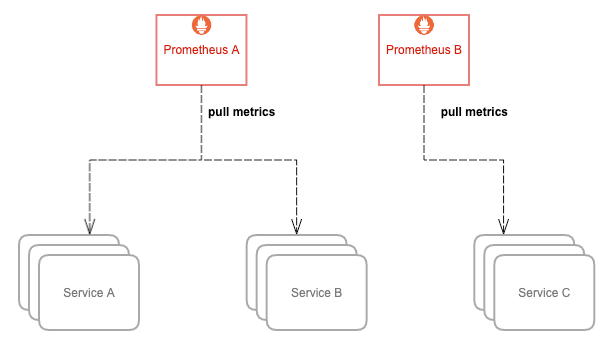
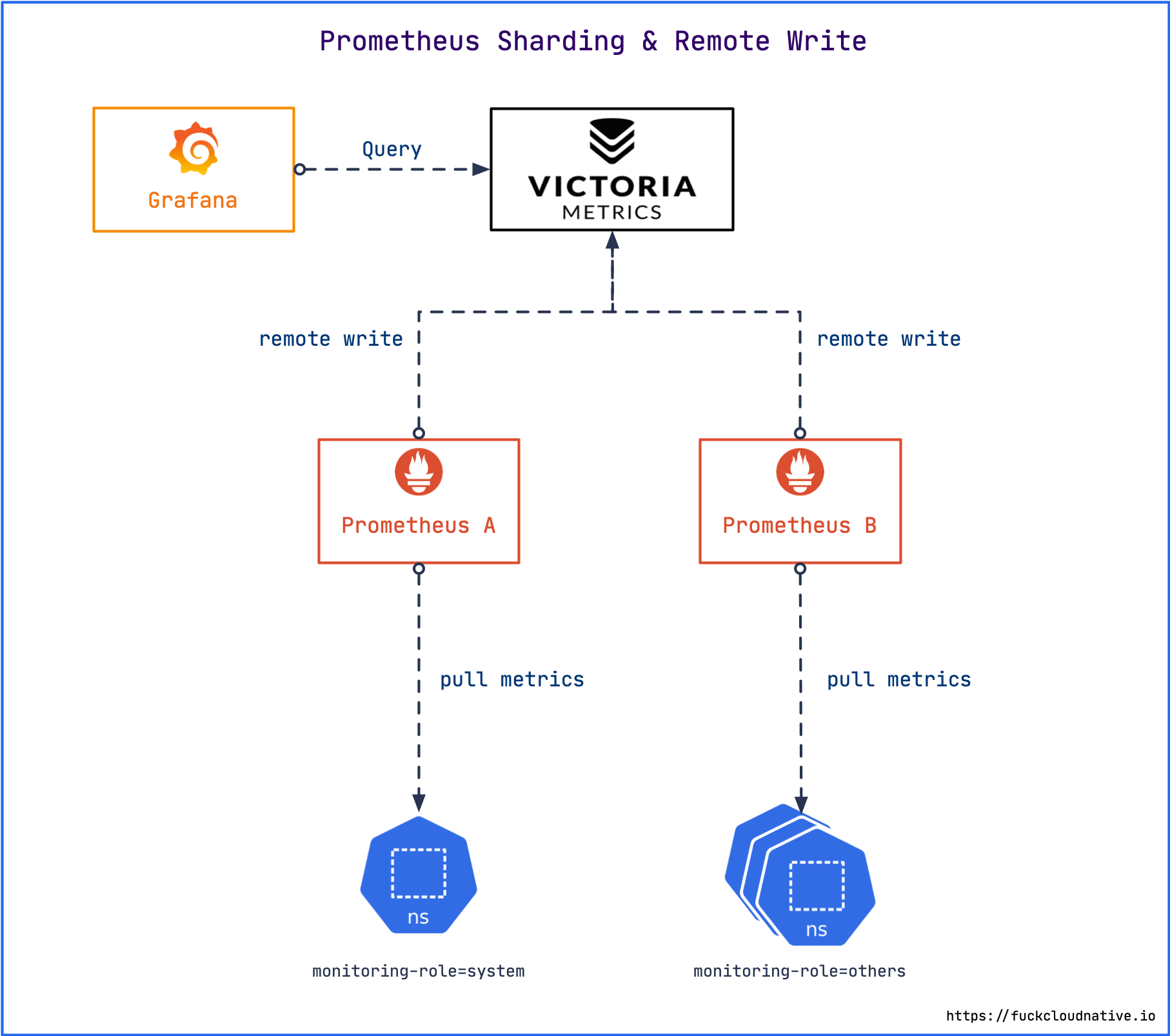
为了解决这个问题,我们可以让 Prometheus 不负责存储数据,只将采集到的样本数据通过 Remote Write 的方式写入远程存储的 Adapter,然后将 Grafana 的数据源设为远程存储的地址,就可以在 Grafana 中查看全局视图了。这里选择
VictoriaMetrics 来作为远程存储。
VictoriaMetrics 是一个高性能,低成本,可扩展的时序数据库,可以用来做 Prometheus 的长期存储,分为单机版本和集群版本,均已开源。如果数据写入速率低于每秒一百万个数据点,官方建议使用单节点版本而不是集群版本。本文作为演示,仅使用单机版本,架构如图:
4. 实践#
确定好了方案之后,下面来进行动手实践。
部署 VictoriaMetrics#
首先部署一个单实例的 VictoriaMetrics,完整的 yaml 如下:
kind: PersistentVolumeClaim
apiVersion: v1
metadata:
name: victoriametrics
namespace: kube-system
spec:
accessModes:
- ReadWriteOnce
resources:
requests:
storage: 100Gi
---
apiVersion: apps/v1
kind: StatefulSet
metadata:
labels:
app: victoriametrics
name: victoriametrics
namespace: kube-system
spec:
serviceName: pvictoriametrics
selector:
matchLabels:
app: victoriametrics
replicas: 1
template:
metadata:
labels:
app: victoriametrics
spec:
nodeSelector:
blog: "true"
containers:
- args:
- --storageDataPath=/storage
- --httpListenAddr=:8428
- --retentionPeriod=1
image: victoriametrics/victoria-metrics
imagePullPolicy: IfNotPresent
name: victoriametrics
ports:
- containerPort: 8428
protocol: TCP
readinessProbe:
httpGet:
path: /health
port: 8428
initialDelaySeconds: 30
timeoutSeconds: 30
livenessProbe:
httpGet:
path: /health
port: 8428
initialDelaySeconds: 120
timeoutSeconds: 30
resources:
limits:
cpu: 2000m
memory: 2000Mi
requests:
cpu: 2000m
memory: 2000Mi
volumeMounts:
- mountPath: /storage
name: storage-volume
restartPolicy: Always
priorityClassName: system-cluster-critical
volumes:
- name: storage-volume
persistentVolumeClaim:
claimName: victoriametrics
---
apiVersion: v1
kind: Service
metadata:
labels:
app: victoriametrics
name: victoriametrics
namespace: kube-system
spec:
ports:
- name: http
port: 8428
protocol: TCP
targetPort: 8428
selector:
app: victoriametrics
type: ClusterIP
有几个启动参数需要注意:
- storageDataPath : 数据目录的路径。 VictoriaMetrics 将所有数据存储在此目录中。
- retentionPeriod : 数据的保留期限(以月为单位)。旧数据将自动删除。默认期限为1个月。
- httpListenAddr : 用于监听 HTTP 请求的 TCP 地址。默认情况下,它在所有网络接口上监听端口
8428。
给 namespace 打标签#
为了限定抓取 target 的 namespace,我们需要给 namespace 打上标签,使每个 Prometheus 实例只抓取特定 namespace 的指标。根据上文的方案,需要给 kube-system 打上标签 monitoring-role=system:
$ kubectl label ns kube-system monitoring-role=system
给其他的 namespace 打上标签 monitoring-role=others。例如:
$ kubectl label ns monitoring monitoring-role=others
$ kubectl label ns default monitoring-role=others
拆分 PrometheusRule#
告警规则需要根据监控目标拆分成两个 PrometheusRule。具体做法是将 kube-system namespace 相关的规则整合到一个 PrometheusRule 中,并修改名称和标签:
# prometheus-rules-system.yaml
apiVersion: monitoring.coreos.com/v1
kind: PrometheusRule
metadata:
labels:
prometheus: system
role: alert-rules
name: prometheus-system-rules
namespace: monitoring
spec:
groups:
...
...
剩下的放到另外一个 PrometheusRule 中,并修改名称和标签:
# prometheus-rules-others.yaml
apiVersion: monitoring.coreos.com/v1
kind: PrometheusRule
metadata:
labels:
prometheus: others
role: alert-rules
name: prometheus-others-rules
namespace: monitoring
spec:
groups:
...
...
然后删除默认的 PrometheusRule:
$ kubectl -n monitoring delete prometheusrule prometheus-k8s-rules
新增两个 PrometheusRule:
$ kubectl apply -f prometheus-rules-system.yaml
$ kubectl apply -f prometheus-rules-others.yaml
如果你实在不知道如何拆分规则,或者不想拆分,想做一个伸手党,可以看这里:
拆分 Prometheus#
下一步是拆分 Prometheus 实例,根据上面的方案需要拆分成两个实例,一个用来监控 kube-system namespace,另一个用来监控其他 namespace:
# prometheus-prometheus-system.yaml
apiVersion: monitoring.coreos.com/v1
kind: Prometheus
metadata:
labels:
prometheus: system
name: system
namespace: monitoring
spec:
remoteWrite:
- url: http://victoriametrics.kube-system.svc.cluster.local:8428/api/v1/write
queueConfig:
maxSamplesPerSend: 10000
retention: 2h
alerting:
alertmanagers:
- name: alertmanager-main
namespace: monitoring
port: web
image: quay.io/prometheus/prometheus:v2.17.2
nodeSelector:
beta.kubernetes.io/os: linux
podMonitorNamespaceSelector:
matchLabels:
monitoring-role: system
podMonitorSelector: {}
replicas: 1
resources:
requests:
memory: 400Mi
limits:
memory: 2Gi
ruleSelector:
matchLabels:
prometheus: system
role: alert-rules
securityContext:
fsGroup: 2000
runAsNonRoot: true
runAsUser: 1000
serviceAccountName: prometheus-k8s
serviceMonitorNamespaceSelector:
matchLabels:
monitoring-role: system
serviceMonitorSelector: {}
version: v2.17.2
---
apiVersion: monitoring.coreos.com/v1
kind: Prometheus
metadata:
labels:
prometheus: others
name: others
namespace: monitoring
spec:
remoteWrite:
- url: http://victoriametrics.kube-system.svc.cluster.local:8428/api/v1/write
queueConfig:
maxSamplesPerSend: 10000
retention: 2h
alerting:
alertmanagers:
- name: alertmanager-main
namespace: monitoring
port: web
image: quay.io/prometheus/prometheus:v2.17.2
nodeSelector:
beta.kubernetes.io/os: linux
podMonitorNamespaceSelector:
matchLabels:
monitoring-role: others
podMonitorSelector: {}
replicas: 1
resources:
requests:
memory: 400Mi
limits:
memory: 2Gi
ruleSelector:
matchLabels:
prometheus: others
role: alert-rules
securityContext:
fsGroup: 2000
runAsNonRoot: true
runAsUser: 1000
serviceAccountName: prometheus-k8s
serviceMonitorNamespaceSelector:
matchLabels:
monitoring-role: others
serviceMonitorSelector: {}
additionalScrapeConfigs:
name: additional-scrape-configs
key: prometheus-additional.yaml
version: v2.17.2
需要注意的配置:
- 通过
remoteWrite指定 remote write 写入的远程存储。 - 通过
ruleSelector指定 PrometheusRule。 - 限制内存使用上限为
2Gi,可根据实际情况自行调整。 - 通过
retention指定数据在本地磁盘的保存时间为 2 小时。因为指定了远程存储,本地不需要保存那么长时间,尽量缩短。 - Prometheus 的自定义配置可以通过
additionalScrapeConfigs在 others 实例中指定,当然你也可以继续拆分,放到其他实例中。
删除默认的 Prometheus 实例:
$ kubectl -n monitoring delete prometheus k8s
创建新的 Prometheus 实例:
$ kubectl apply -f prometheus-prometheus.yaml
查看运行状况:
$ kubectl -n monitoring get prometheus
NAME VERSION REPLICAS AGE
system v2.17.2 1 29h
others v2.17.2 1 29h
$ kubectl -n monitoring get sts
NAME READY AGE
prometheus-system 1/1 29h
prometheus-others 1/1 29h
alertmanager-main 1/1 25d
查看每个 Prometheus 实例的内存占用:
$ kubectl -n monitoring top pod -l app=prometheus
NAME CPU(cores) MEMORY(bytes)
prometheus-others-0 12m 110Mi
prometheus-system-0 121m 1182Mi
最后还要修改 Prometheus 的 Service,yaml 如下:
apiVersion: v1
kind: Service
metadata:
labels:
prometheus: system
name: prometheus-system
namespace: monitoring
spec:
ports:
- name: web
port: 9090
targetPort: web
selector:
app: prometheus
prometheus: system
sessionAffinity: ClientIP
---
apiVersion: v1
kind: Service
metadata:
labels:
prometheus: others
name: prometheus-others
namespace: monitoring
spec:
ports:
- name: web
port: 9090
targetPort: web
selector:
app: prometheus
prometheus: others
sessionAffinity: ClientIP
删除默认的 Service:
$ kubectl -n monitoring delete svc prometheus-k8s
创建新的 Service:
$ kubectl apply -f prometheus-service.yaml
修改 Grafana 数据源#
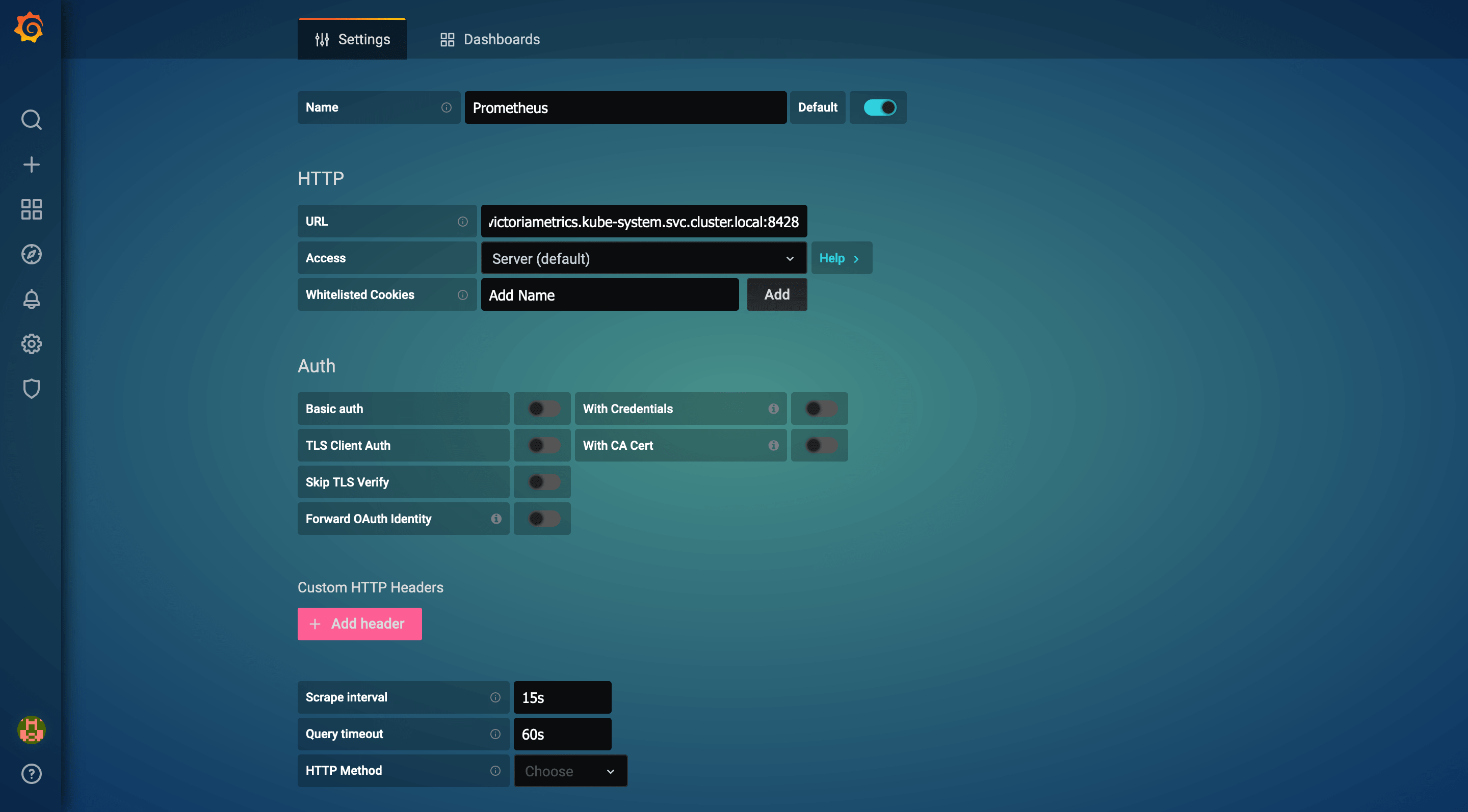
Prometheus 拆分成功之后,最后还要修改 Grafana 的数据源为 VictoriaMetrics 的地址,这样就可以在 Grafana 中查看全局视图,也能聚合查询。
打开 Grafana 的设置页面,将数据源修改为 http://victoriametrics.kube-system.svc.cluster.local:8428:
点击 Explore 菜单:
在查询框内输入 up,然后按下 Shift+Enter 键查询:
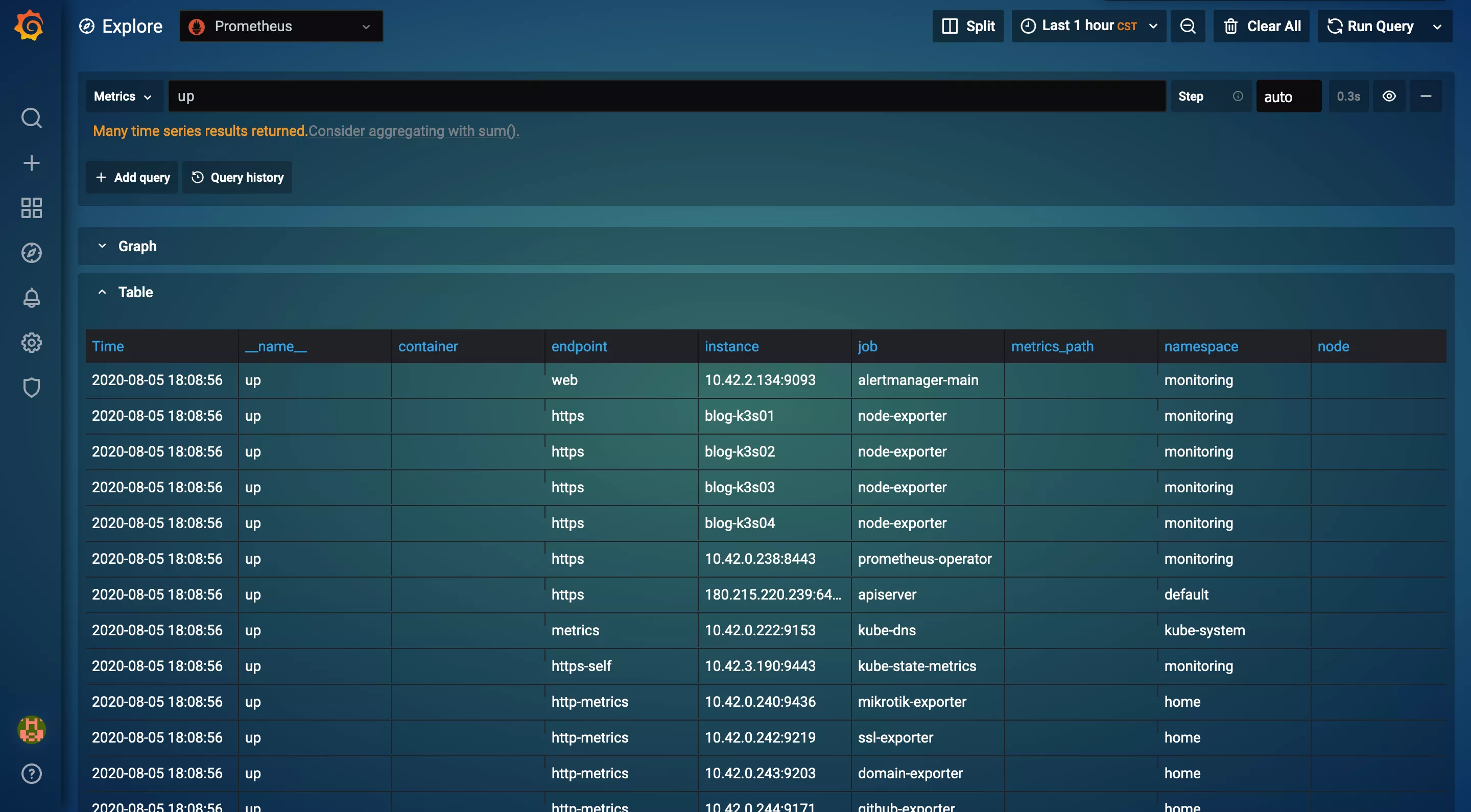
可以看到查询结果中包含了所有的 namespace。
写这篇文章的起因是我的 k3s 集群每台节点的资源很紧张,而且监控的 target 很多,导致 Prometheus 直接把节点的内存资源消耗完了,不停地 OOM。为了充分利用我的云主机,不得不另谋他路,这才有了这篇文章。